Mark van Lent’s weblog2024-10-16T19:58:33+00:00tag:markvanlent.dev,2010-04-02:/index.xmlMark van Lenthttps://markvanlent.dev/about/Copyright (c) Mark van Lent, Creative Commons Attribution 4.0 International License.https://markvanlent.dev/favicon.ico<![CDATA[PyGrunn 2024]]>https://markvanlent.dev/2024/05/17/pygrunn-2024/2024-05-17T16:42:29Z2024-05-17T00:00:00ZNotes from my day at the 12th edition of PyGrunn.
PyGrunn is a Python focussed, one day conference held in
Groningen1. Or as the organizers more eloquently phrase this:
PyGrunn is the “Python and friends” developer conference with a local
footprint and global mindset. Firmly rooted in the open source culture, it
aims to provide the leaders in advanced internet technologies a platform to
inform, inspire and impress their peers.
Before I start with my notes I want to give a shout-out to Reinout van Rees.
His (PyGrunn) summaries
are excellent. I’m always impressed by the quality of them and how little time
he needs to write them. Where I’m only able to make notes and need to write them
out afterwards, Reinout has the summary (as a coherent story) ready before the
speaker has unhooked their laptop. So if you are interested in one of the talks
he has attended, head over
there first.
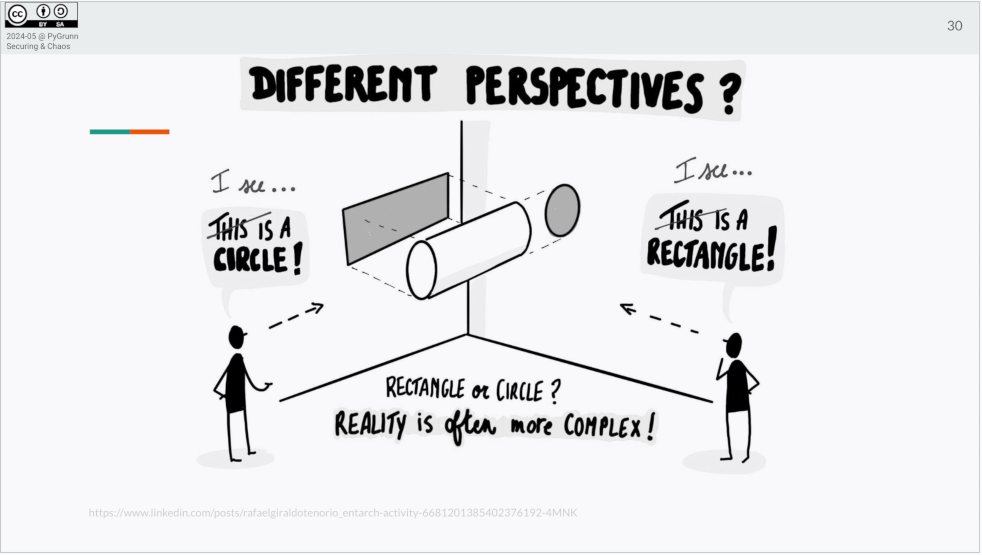
Why do platform engineering teams exist? We’ve seen a “shift left” of
responsibilities towards the developer e.g. QA, operations (DevOps). But we
(software developers) are trained to write code, not to e.g. monitor it.
So where does a humble developer start? There is an abundance of choices on the
tools to use. What do you pick for package management? Or continuous
integration? Or deployment, code quality, observability, etc. This freedom of
choice comes with a cost. We start with discussing which tools to use instead of
the problem the customer is facing. And depending on which choice we make, the
result may make reasoning about the software more complex.
So what should you do?
Andrii broke it down into three parts:
You observe (i.e. you read a lot to get the lay of the land)
You execute (this is the actual software development part)
And then you collect feedback (you reach out to teams, you observe how their work has changed)
Some of the platform engineering team deliverables:
The “consumers” are developers, compliance teams and other platform teams. The
goal is to:
Have reasonable defaults
Remove redundancy
Keep things consistent
To get a feel for the scale of things: at Andrii’s company there are over 160
services, developed on by 300+ developers in 500+ repositories. They total up
to 3 million lines of code and 6 million lines of YAML.
Templates (boilerplates) provide a paved path. The goal is to have teams spend
as little time as possible when starting a project. The templates use a certain
set tools that are supported. Teams are free to use different tools though if
they want to.
Andrii uses cookiecutter
templates at work. It’s not his choice perse, but it’s what was already in place
when he joined. There are currently three templates in use. They have evolved
over time. For example in the last nine years, over 800 changes have been made
(that is more than one change per week on average).
The evolution has left its marks: the templates have a lot of code duplication.
There is also code specific to a tiny minority of projects (only about 8 out of
the 500+). This means that most projects start with deleting code after using
the boilerplate.
And that also relates the downside of using cookiecutter the way they do. Instead of
just using it to get started with a project, they also use it incrementally. But
cookiecutter does not have versioning built-in. So if you remove a file and then
reapply cookiecutter again, the file is happily created again.
While Andrii is aware of the issues (and thinks
copier might be a better alternative),
it is hard to replace practices that are already in use. And cookiecutter is
great for getting started with a project.
With regard to the standardization, they use the following in the templates:
pyproject.toml for all projects
Poetry (instead of setuptools + pip-tools)
sprinkle Renovate on top for
automatically updating dependencies
As it currently stands, there are 99 project that migrated to pyproject.toml and
Poetry in the last 2 years. It makes sense because it takes time for projects to
transition. Plus they are not required to migrate; again: the template are there
to help, not to limit the users. Renovate has been adopted more quickly.
Migrating from e.g. pkg_resources to pkgutil or
PEP-420 for namespaces packages is hard.
Templates can help with that. However, cookiecutter does not actually manage
files. So if a file has been removed from a template, rerunning cookiecutter
does not remove the file from the project. So that requires some care.
When they migrated from a monolithic application to a microservices
architecture, authentication/authorization became an issue. There was no
visibility for teams, no transparency and no accountability. To combat this, they
created an API where applications can declare the required access and scopes
in a YAML file. Maintainers can approve this access. And this also allows for
CI/CD to check access. A CLI tool can verify the validity of the YAML and check
if access is actually approved.
Securing your team, solution and company to embrace chaos — Edzo Botjes
Edzo started by sharing a link to
his slides
and warned us that it usually takes two weeks for people to digest the contents
of his talk. He would overload us with information. And that’s where I decided
to solely concentrate on the talk and not on note taking.
Nobody knows what they are doing. Embrace this.
Even a simple, deterministic system like a double
pendulum has a nondeterministic
outcome. In other (my) words: the whole world is in chaos and unpredictable.
When presented with information everyone processes it differently and
understands something else (also see viral phenomenon of the dress).
What worked for Edzo was to embrace chaos. To do this he let go of his desire to
control and trying to create a predictable outcome.
Descriptors: Decoding the Magic — Alex Dijkstra
Many people have used descriptors without them even being aware of it.
From the documentation:
Descriptors let objects customize attribute lookup, storage, and deletion.
You can view descriptors as reusable @properties. A descriptor implements the __get__ and
__set__ methods (and when needed __delete__).
Alex showed a bunch of examples. This is the template he showed to introduce
descriptors:
classMyDescriptor:def__get__(self,obj,owner):# owner is the class to which the instance belongsreturnobj.__dict__.get(self.private_name)def__set__(self,obj,val):# self is descriptor instance.obj.__dict__[self.private_name]=valdef__set_name__(self,owner,name):self.public_name=nameself.private_name=f'_{name}'
Using descriptors you can do things when getting or setting the value. E.g. in a
class you can enforce that an attribute has a certain type.
The __set_name__ method was introduced in Python 3.6. It is not needed to use this in all of your
descriptors, but also doesn’t hurt.
Do you want to use descriptors all over the place? No. They can be useful: you
can create a clean APIs with them and this helps if the API is used frequently.
However, it does create some overhead and the code is a bit more complex.
Luciano Ramalho’s book
Fluent Python
(Luciano also did a few talks about descriptors)
Release the KrakenD — Erik-Jan Blanksma
KrakenD is an API gateway product. Erik-Jan likes it
so much he wanted to share his experience with it.
Projects can start out simple, with a monolith that is accessed via a web
client. Before you know it, there are several services and multiple types of
clients. The solution is to introduce an API Gateway in the middle. It can then
handle the incoming requests.
API Gateway in short:
It sits between clients and backend (as a sort of portal).
It hides internal complexity of backend for the clients.
The gateway is a great place to introduce things like
authorization/authentication, logging, load balancing, caching, etc.
KrakenD is one of the available API Gateways. It is open source, but there’s
also an enterprise version with extra features. KrakenD is implemented in Go and
offers a bunch of features out of the box (monitoring, throttling, request and
response manipulation). KrakenD offers integrations with e.g. tools (Jaeger,
Grafana, the Elastic stack), authorization/authentication services and queues
(RabbitMQ).
KrakenD is a stateless process, so no database is needed. It takes JSON (or
YAML) config. It can combine the results of multiple backends API calls and
return it as a single response.
Tips:
Use the KrakenDesigner (makes it easy to explore what’s possible). Note that
you do not want to use this in production.
You’ll want to split up the configuration when it grows. By using flexible
configuration you can combine so called partials, settings and templates.
KrakenD can check and even audit you configuration.
Since the configuration is in JSON, you can generate
OpenAPI.json from the KrakenD config. You can use this for Swagger.
KrakenD is a great tool to manage your APIs. It is lightweight, fast, easy to
configure and has lots of functions out of the box. It is versatile and
extensible. By using it you can make your architecture more agile.
However, it also means that you will have to manage the API Gateway
configuration. And a change in the configuration means you will have to restart
the process.
It can be helpful use functional programming (e.g. using closures) instead of
by default using classes and methods.
“Grunn” is what Groningen is called in the regional language ↩︎
]]><![CDATA[Custom Kali Linux ISO — part 2]]>https://markvanlent.dev/2024/02/13/custom-kali-linux-iso-part-2/2024-02-13T20:03:46Z2024-02-13T00:00:00ZIn part 1 of this (mini) series I
described what I did to be able to build an ISO image using Vagrant. Now it’s
time to actually customize it.
I’ll show what I have done and will provide links to the official documentation
for more in-depth information. This post is mainly for my own reference in the
future, but others might benefit from it as wel.
The basis is an existing Kali Linux environment which is setup with the build
script. See the
Getting Ready
section of the documentation. Long story short:
You can include extra packages on your custom Live ISO. If these are available in the
Kali repos, it is quite simple. As described in the
documentation
you can edit the files (in case of the default Live ISO) in
kali-config/variant-default/package-lists/kali.list.chroot. I decided to put
the additional packages in a new file:
The first command creates a file with the .chroot extension and is used during
the chroot stage. To also have this file on the live system (to be able to use
APT later on to update the packages), I copy the .chroot file to one ending in
.binary. For more information on this subject, see the Debian documentation pages
Customization overview
and
Customizing package installation.
The APT repository signing key also needs to be stored in the same directory:
There’s one more change that needs to be made. To make sure the build process
can actually use the packages from the added repository, you’ll need to include a
few more packages at boot time.
To do this, edit the file auto/config and add an --include option to the
debootstrap-options line. Concretely this means changing this line:
After that you are good to go. Just do not forget to add the package you want to
install (in this case code) to the list of packages. In my case this meant
updating kali-config/variant-default/package-lists/custom.list.chroot.
]]><![CDATA[Custom Kali Linux ISO — part 1]]>https://markvanlent.dev/2024/02/11/custom-kali-linux-iso-part-1/2024-02-13T20:03:46Z2024-02-11T00:00:00ZWhen I wanted to create a custom Kali Linux ISO using Vagrant, the allocated
disk was not big enough. Solving this required some searching and putting
several bits of information together. This post shows how I increased the disk
size.
The Kali documentation contains a nice page about creating a custom Kali
ISO. That
page states that [i]deally, you should build your custom
Kali ISO from within a pre-existing Kali environment, […] so I
decided to use Vagrant to create a virtual machine
which I could use.
The basic configuration for that box:
Vagrant.configure("2")do|config|config.vm.box="kalilinux/rolling"config.vm.provider"virtualbox"do|vb|# Do not display the VirtualBox GUI when booting the machinevb.gui=falseendend
When I started building the ISO, the default 40G disk filled up and the process
could not be completed.
To solve this, the first step was to have Vagrant resize the disk for the
machine. You can do this by adding a single line to your configuration.
(For details see the relevant
Vagrant documentation.)
Vagrant.configure("2")do|config|config.vm.box="kalilinux/rolling"config.vm.disk:disk,size:"50GB",primary:trueconfig.vm.provider"virtualbox"do|vb|# Do not display the VirtualBox GUI when booting the machinevb.gui=falseendend
While this increases the size of the disk, I still had to increase the
partition in the OS. This was a bit more involved, but by adding a couple of
commands in a config.vm.provision section, I got it working without needing to
reboot the machine afterwards:
Vagrant.configure("2")do|config|config.vm.box="kalilinux/rolling"config.vm.disk:disk,size:"50GB",primary:trueconfig.vm.provider"virtualbox"do|vb|# Do not display the VirtualBox GUI when booting the machinevb.gui=falseendconfig.vm.provision"shell",inline:<<-SHELL
apt-getupdateapt-getinstall-ycloud-guest-utilsswapoff-aecho'+10G,'|sfdisk--move-data--force/dev/sda-N2partprobegrowpart/dev/sda1resize2fs/dev/sda1swapon-aSHELLend
Running “vagrant up” now does all the heavy lifting for you. Do note that
resizing the disk and making the extra space available to the OS takes
significantly more time when creating the machine (compared to using a machine
with the default disk size). Then again: if you know this, you can plan to have
a cup of coffee (or tea if you are like me) in that time.
Time to create a custom Kali ISO… See
part 2 for how I added extra
packages to the ISO.
]]><![CDATA[Open tabs — December 2022]]>https://markvanlent.dev/2022/12/30/open-tabs-december-2022/2022-12-30T22:58:20Z2022-12-30T00:00:00ZThe end of the year is a nice time to review my open tabs on my phone and
computer to see what’s worth saving and what is not. So here is
another round.
Note that I do not necessarily endorse the articles or applications I link to.
Most of the links to tools are here specifically because they seem interesting
to me, but I have no actual experience with them—hence the need for a reminder
on this list.
I have tried to group the links somewhat, but other than that they are listed in
more or less random order.
From the README: gron transforms JSON into discrete assignments to make it
easier to grep for what you want and see the absolute ‘path’ to it. It eases the
exploration of APIs that return large blobs of JSON but have terrible
documentation.
I had to (or wanted to) switch from using the name “master” for my main branch
to something else (“main” in most cases) for a couple of Git repositories. It is
not hard, but if you do not do it often, it is convenient to have a guide like this
to make sure you do not forget anything.
If you do not like the idea of automatically updating your containers with
Watchtower, you might want to look at this Docker Image Update
Notifier application.
I’m already running a Gitea instance and a
Docker Registry. Drone might be a nice
third component to automatically build projects and e.g. create Docker images
and push them to my internal registry.
I am already using a private certificate authority to create certificates for
the services in my homelab, but it would be nice to have a self hosted
ACME server to do the tedious work.
This tool might be what I need.
While officially a movie/series recommendation engine I use
this site regularly to check if I can stream a movie or series in my country and
if so, on which service it is available.
A book series by Scott Jucha, tipped in the
Security Now podcast. (The series is
mentioned in episode 887 for the first
time.) I’ve finished the first book and loved reading it!
I’m in the process of testing this backup tool to see if I want to switch over
to restic from my current rsync based script to backup my Linux machines to an
external disk. If I go that route, I’ll also have to have a look at
restic-tools.
When I was perparing my CV and a cover letter, I wanted the resulting PDF to
be more accessible. This article gave me useful instructions on how to achieve
that.
I’m toying with the idea of upgrading my home office with some LED
strips. Perhaps I’ll use Neopixels and a Raspberry Pi (or similar board) to do
this.
An article about how you can help your manager (help you).
]]><![CDATA[AWS CLI tools I've used]]>https://markvanlent.dev/2022/12/07/aws-cli-tools-ive-used/2022-12-07T20:47:08Z2022-12-07T00:00:00ZA quick post (mostly for myself) to list the command line tools I’ve used over
the years to interact with AWS, besides the official AWS Command Line Interface
(AWS CLI).
I was content with the AWS CLI initially, but once I had enabled and required
multi-factor authentication (MFA), using the AWS CLI became a bit of a nuisance.
So I started using aws-mfa. I also
wrote a post about it here, titled Using MFA with AWS
CLI.
The next tool I started using was Awsume. This Python
package makes it easier to manage your AWS credentials and sessions, especially
if you are accessing more than one account.
Once we started using Single Sign-On (SSO) more and more at work, I switched to
using AWS Vault. I think the
reason I switched to AWS Vault was simply because Awsume did not support SSO,
but to be honest, I am not sure about that. (Neither do I know if Awsume
supports SSO at the moment.) Either way, what I really like about AWS Vault is
that it stores the credentials in an encrypted password store. So I no longer
had credentials lying around on my hard drive in plain text.
After reading the article
Taking AWS Account Logins For Granted,
I also switched to using Granted. In contrast to AWS
Vault, Granted does not seem to have a way to securely store your long lived
credentials. If you are using those, you may want to use AWS Vault for those.
Since both tools use the same ~/.aws/config file, you can use them next to each
other without a problem.
And that’s the current state of affairs for me. Since I effectively only deal
with SSO logins, I use Granted and its assume command for my day-to-day.
Combined with the
Granted add-on for Firefox
I can easily use multiple accounts and roles on the command line and in my
browser.
]]><![CDATA[All Day DevOps 2022]]>https://markvanlent.dev/2022/11/10/all-day-devops-2022/2022-11-10T21:32:11Z2022-11-10T00:00:00ZToday was the 7th All Day DevOps. Just like
last year the organizers managed to get 180
speakers, spread over 6 tracks, to inform, teach and entertain us. As usual I
made some notes of the talks that I attended.
Keynote: The Rise of the Supply Chain Attack — Sean Wright
Dependency managers (like Apache Maven) changed the way software is being
developed: using those makes it much easier to use dependencies in your
application (you don’t have to fetch them manually yourself). As a result,
building your own libraries is now less common, using an available (open source)
library is much easier.
To get a feel for the scale: NPM serves 2.1 trillion annual downloads
(requests). This obviously includes automatic builds, but the growth over the
last couple of years has been exponential none the less. And using third party
libraries can be a very good thing. Good libraries can be much more secure and
have less bugs than some library developed in house.
Types of supply chain attacks:
Dependency confusion
Register a private package (which you know is used by a company) in a public
repository. If the package manager searches for the package in the public
repository before the private one, the malicious package is used.
Typo squatting / masquerading
Use misspelled or “familiar” names in the hopes someone uses the wrong package.
Malicious package
Malicious payload in a package that promises (and perhaps even delivers)
useful functionality.
Malicious code injection
Compromise of an existing package (e.g. by compromising the build system or
repository).
Account takeover
Malicious actor can log in as the original author.
Exploiting vulnerabilities in packages
Using a known or unknown vulnerability in a library.
Protestware
For example a legitimate library with notes protesting against the war in
Ukraine.
After this Sean unfortunately dropped from the session.
Taking Control Over Cloud Costs — Amir Shaked
Reasons to analyze your cloud costs:
Costs translate to profit
Usage is directly tied to costs (and if you don’t properly monitor, your spend
could increase unexpected)
Be in control: by monitoring you can determine what impact certain actions
have on your business
Be intelligent: by knowing what you spend where, you can connect it to your
business KPIs
Save money
You’ll want to be aware when you scale (hyper growth) if your costs grow faster
than the number of users/sales/etc. You don’t want to end up in a situation
where more success means less profit.
Things to look for in your environment:
Unused resources
Over commitment
Under commitment
Price per unit we care about (e.g. users, sales, etc)
Bugs
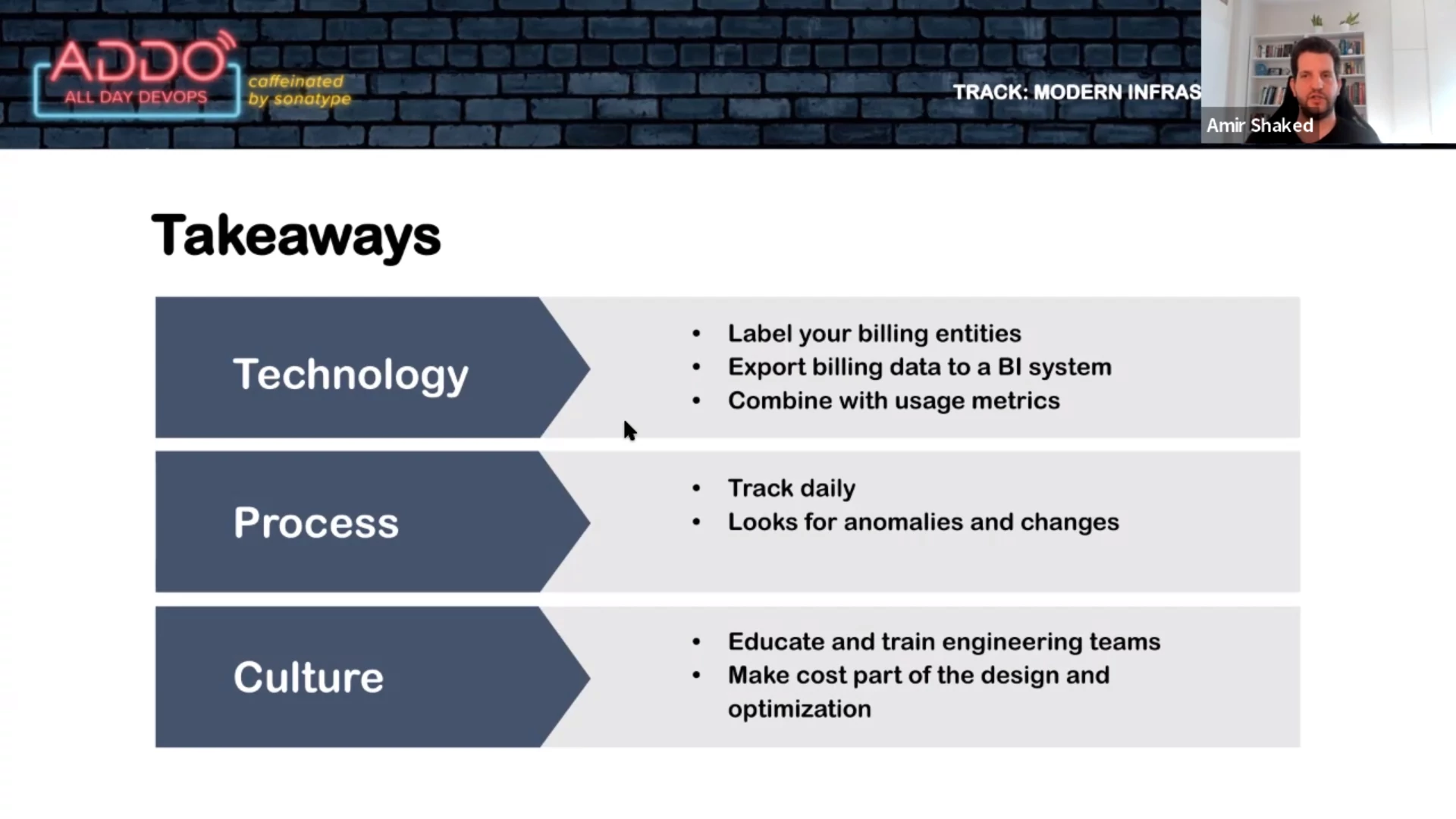
Best practices you can arrange from day one:
Export billing data and create e.g. dashboards
Structure and organize resources for fine-grained cost reporting
Configure policies on who can spend and who has administrator permissions
Have a culture of “showback” in your organization. Make your employees aware of
the costs, have budgets and alerts.
Beyond Monitoring: The Rise of Observability Platform — Sameer Paradkar
Customer experience is important for your revenue. You need to deliver your
service and make sure you know how well you’re able to do so. Observability
helps you find the needle in the haystack, identify the issue and respond before
your customers are affected.
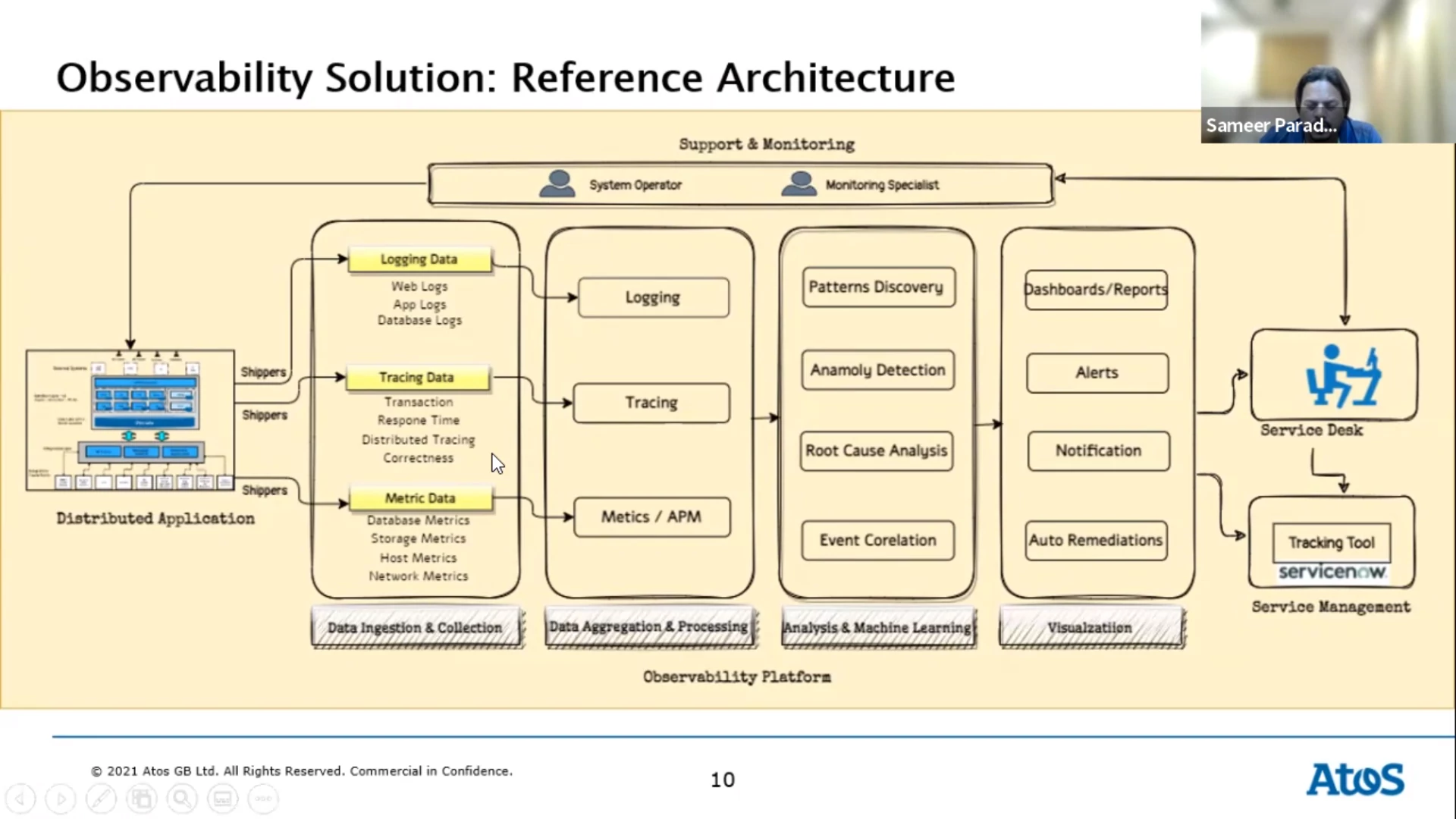
Pillars of observability:
Metrics
Numeric values measured over time. Easy to query and retained for longer periods.
Logs
Records of events that occurred at a particular time (plain text, binary,
etc). Used to understand the system and what’s going on.
Traces
Represent the end-to-end journey of a user request through the subsystems of
your architecture.
Relevant key performance indicators (KPIs) and key result areas (KRAs):
Customer experience
Mean time to repair (MTTR)
Mean time between failure (MTBF)
Reliability and availability
Performance and scalability
An observability platform gives you more visibility into your systems health
and performance. It allows you to discover unknown issues. As a result you’ll
have fewer problems and blackouts. You can even catch issues in the build phase
of the software development process. The platform helps understand and debug
systems in production via the data you collected.
AIOps applies machine learning to the data you’ve collected. It’s a next stage
of maturity. Its goal is to create a system with automated functions, freeing up
engineers to work on other things. Automating remediation of issues can also
greatly reduce response time and mean time to repair. This means that the
customer experience is restored faster (or is never degraded to begin with).
Failure Is Not an Option. It’s a Fact — Ixchel Ruiz
Failure can cause a deep emotional response, we can get depressed and it can
make us physically sick. On one side of the spectrum, a failure can cause harm
to other people. On the other side we could embrace failure and make things safe to
fail. Failure in IT on the project level is quite common. Failure can also
happen on a personal level.
Not all failures are created equally. There are three types:
Preventable
These are the “bad” failures. There’s no reason to allow these.
Complexity related
These failures are due to the inherent uncertainty of work. Usually it is a
particular combination of needs, people and problems that cause them.
Intelligent
The “good” failures, since they provide new knowledge.
Steps to learn from failures:
Recognize
Understand the cause
Extract lessons to prevent future failure
Share the information
Practice for the next failure in a safe and controlled setting
Increase return by learning from every failure, share the lessons and review the
pattern of failures. Do note that none of this can happen in an environment without
psychological safety. You need to feel safe to discuss your failure, doubts or
questions to be able to learn.
Accurate Metrics — Christina Zeller and Marcus Crestani
A manufacturing process was monitored and there was a nice dashboard to show
whether there were any problems. However, at a certain moment there was a
problem, but the dashboard was still claiming everything was fine.
What was going on? Unreliable network? Erratic monitoring system? Flawed
collection of metrics? It turned out to be all of them.
Sampling rates, retention policy and network issues can cause missing
measurements in your time series database. This missing information can cause a
drop in failure rate if you are unlucky enough that the missing samples are
failed ones. So you think everything is fine, but there is something wrong in
your environment.
Modelling metrics differently can help. One possible improvement is to have a
duration sum in your metrics instead of just the duration. If you now miss a
sample, the sum will still indicate that there has been a failure.
Using histograms is even better since you place values in buckets, e.g. failures
in our case. A disadvantage however is that the metrics creation system must now
also know what qualifies as a success or failure.
Takeways:
Always collect metrics
Check that your metrics match reality
Always consider missing data
For duration metrics always use histograms
After improving their metrics, the monitoring system matches the actual state of
the manufacturing environment again.
Why Is It Always DNS, TLS, and Bad Configs? — Philipp Krenn
DNS, TLS and bad config are where failures are waiting to haunt us when we least
expect it. We need to have a tool to find the issues in our system early on.
Health checks can be this essential tool to alert us.
You are able to narrow down where the issue is if you structure your health
checks like this:
Outside the network (different provider)
This allows you to detect issues with e.g. DNS, the uplink, a firewall, a load
balancer, service availability and latency.
On the network (different AZ)
If you are on the network, you could see issues with the network, firewall,
TLS, service availability and latency. You can compare your measurements from
outside with what you see on the inside.
On the instance
Again, by comparing the local point of view with the outside, you can detect
issues with service availability, proxy vs service, latency, dependencies
(e.g. a database that is slow or the service cannot reach)
Examples of tests you can use:
Ping a host
Setup a TCP connection
Do an HTTP request
POST data to a service
Synthetic monitoring where you simulate button clicks
Health checks are cheap to run and give you a fast overview. They do not
replace observability and only tell you something is broken, not what is going
on. Start simple and only add synthetics when/where needed since they more
complex.
Comprehending Terraform Infrastructure as Code: How to Evolve Fast & Safe — Anton Babenko
By using Terraform AWS modules
you’ll have to write less Terraform code yourself, compared to using the
AWS provider resources directly.
For example: if you write your own Terraform code from scratch for an example
infrastructure with 40 resources, you’ll need about 200 lines of code. Once you
introduce variables, that code base will grow to 1000 lines of code. When you
then split it up into modules, you’ll need even more code.
Instead, if you use terraform-aws-modules you’ll have more features than your
own modules would only need about 100 lines of code.
Questions with regard to terraform-aws-modules:
Why?
Understandability is an important issue. To help with these questions (like
“why is it done this way?") there are autogenerated documentation and diagrams. A
visualization of the dependencies also helps.
Does it work?
The project focusses on static analysis (using tflint and
terraform validate) and running Terraform on examples. Anton thinks that testing
code should be for humans (so HCL is better than Go).
How to get feedback quicker?
Options: run Terraform locally instead of in CI/CD pipeline, simplify the
code, and restrict surface area of your code using policies, guardrails, etc.
Split up your Terraform code, with different states, to speed up Terraform
runs.
Most important word for this talk: understandability.
50-67% of time for software projects spent on maintenance.
Keynote: Journey to Auto-DevSecOps at Nasdaq — Benjamin Wolf
Why DevOps? It can be pretty complicated to explain, even though it is an
obvious choice for Nasdaq. For most people Nasdaq is a stock exchange but it is
actually a global technology company. Sure, they run the stock exchange, but
also provide capital access platforms and protect the financial system.
Nasdaq develops and delivers solutions (value) for their users. They manage and
operate complex systems. It has been around for a while. So again, why DevOps?
The answer is: to get better at their practices.
They want to deliver solutions (value) to their users efficiently, reliably and safely.
They want to manage and operate complex systems efficiently, reliably and safely.
Years ago they had manually configured static servers and the development teams
were growing. They automated software deployment to a point where the product
owners could trigger the deployment, and even pick which branch to deploy. This
was an important first evolution. They had a “DevOps team” to handle this
automation.
The second evolution for Nasdaq was moving from a data center to the cloud,
using infrastructure as code (IaC). The question they asked themselves was what
to do first: migrate to cloud or get their data center infrastructure 100%
managed via IaC? They made the ambitious decision to do both at once.
By turning your infrastructure into code, you can create and destroy the
environment as many times as you like. And this was welcome: after about 2100
times they “got it right” and were able to move over the production environment
to the cloud. Without IaC this would not have been possible as flawlessly as it
did.
The cloud and IaC brought them:
Efficiency: maintenance, patching, capacity
Reliability: self-healing, immutable
Safety: immutability, destroy/create
Over time the DevOps team started to handle a lot more work. The team consisted
of system administators, but they were required to work as developers (make code
reusable, use git, etc). The DevOps team started to complain about being
overloaded and they became a bottleneck since a lot of development teams came to
them with problems (failing builds, cloud questions).
On the other side, the development teams stared to complain because they are
dependent on the DevOps team but that team had become the bottleneck. And “just”
scaling up the DevOps team would not solve the problem.
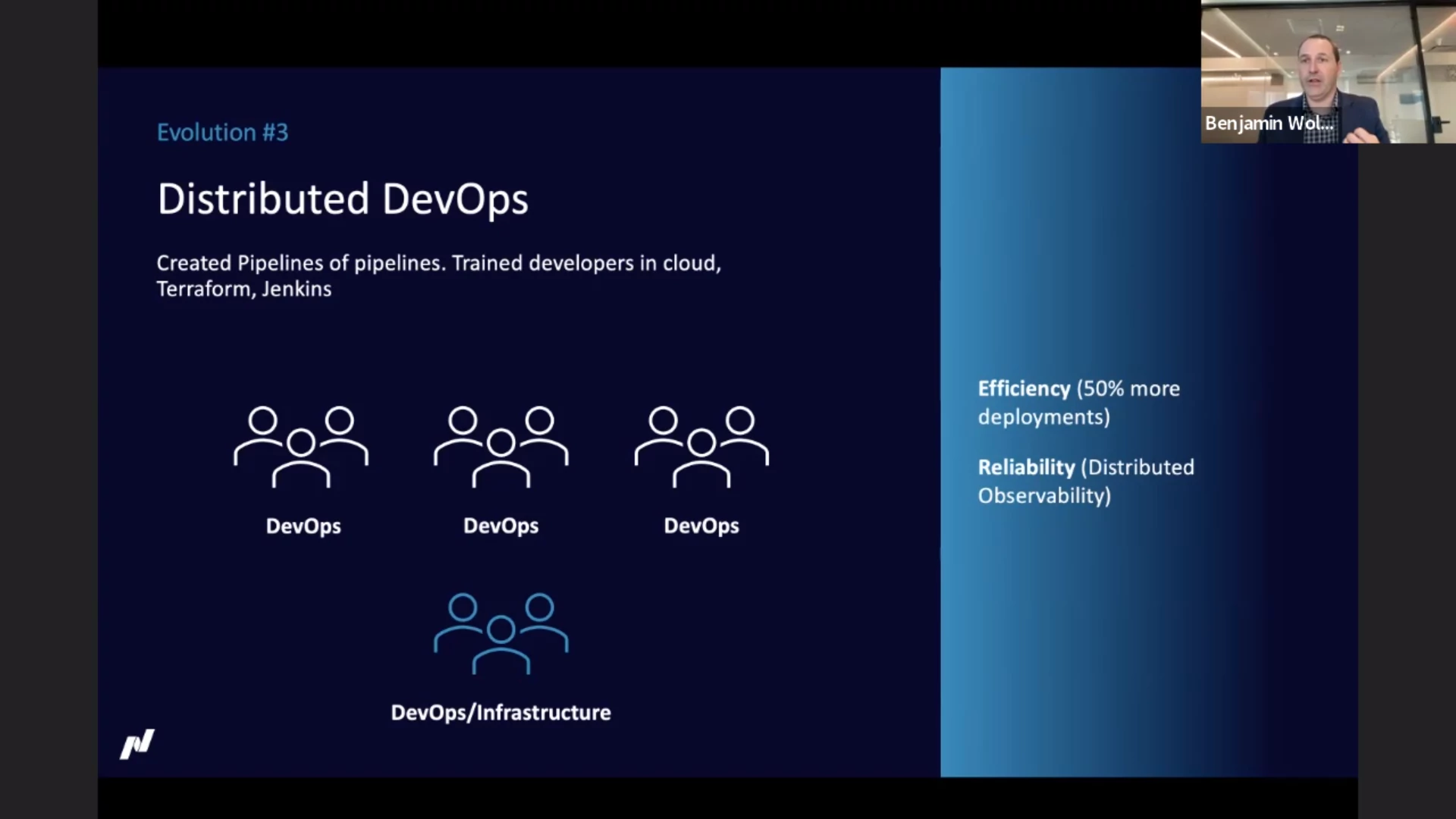
Where the second evolution was about the technology, the third evolution was about
efficiency. They moved to a “distributed DevOps” model. Developers were
empowered: access to logs and metrics, training (cloud, Terraform, Jenkins). By
creating a central observability platform, developers could get insight in what
is going on, without the need to have access to the production environment.
This resulted in more deployments and enhanced reliability of the deployments
because of the observability platform.
A year or three later, new cracks appeared. Standards were diverging because
teams were allowed to pick their own path (libraries, databases, pipelines,
Terraform code, etc). It also lead to practices that needed to be fixed (e.g.
lack of replication). Standardizing this led to quite a burden at the start of a
project: lots of basic stuff to setup.
Developers needed to be experts in a lot of technology, from JavaScript and the
JavaScript framework in use, via multiple .NET versions to Terraform and other
deployment related tech. An easy way to solve this situation was to flip back to
the previous situation with a single team responsible for deployment and such.
But this would basically mean recreating the bottleneck.
The ownership itself was not the problem. The efficiency was, because of the
boilerplate needed for teams. Stuff you want to do the same across the teams.
They wanted to empower the development teams, but also give them the standards
for databases, messaging, etc. Instead of copying a template and have teams
diverge afterwards, they looked into packaging to also make it easier to update
afterwards.
This lead to evolution four with marker files, packages, code generators and
auto-devops pipelines. The pipeline looks at the markers (“hey, this is a .NET
app”) and can then apply a standard pipeline. Nasdaqs code generators create the
boilerplate for the teams so within two minutes of starting with a new
application you’re able to write code to solve your business problem, instead of
having to create boilerplate code yourself first.
The developers can get up and running quickly, but in a safe way.
The development teams are all DevOps teams now, but Nasdaq also has a
specialized team for the complex areas (hardware, networking, etc). There is
also a “developer experience” team that focusses on the tools for the
developers, like the code generators.
Current status with regard to our three key areas:
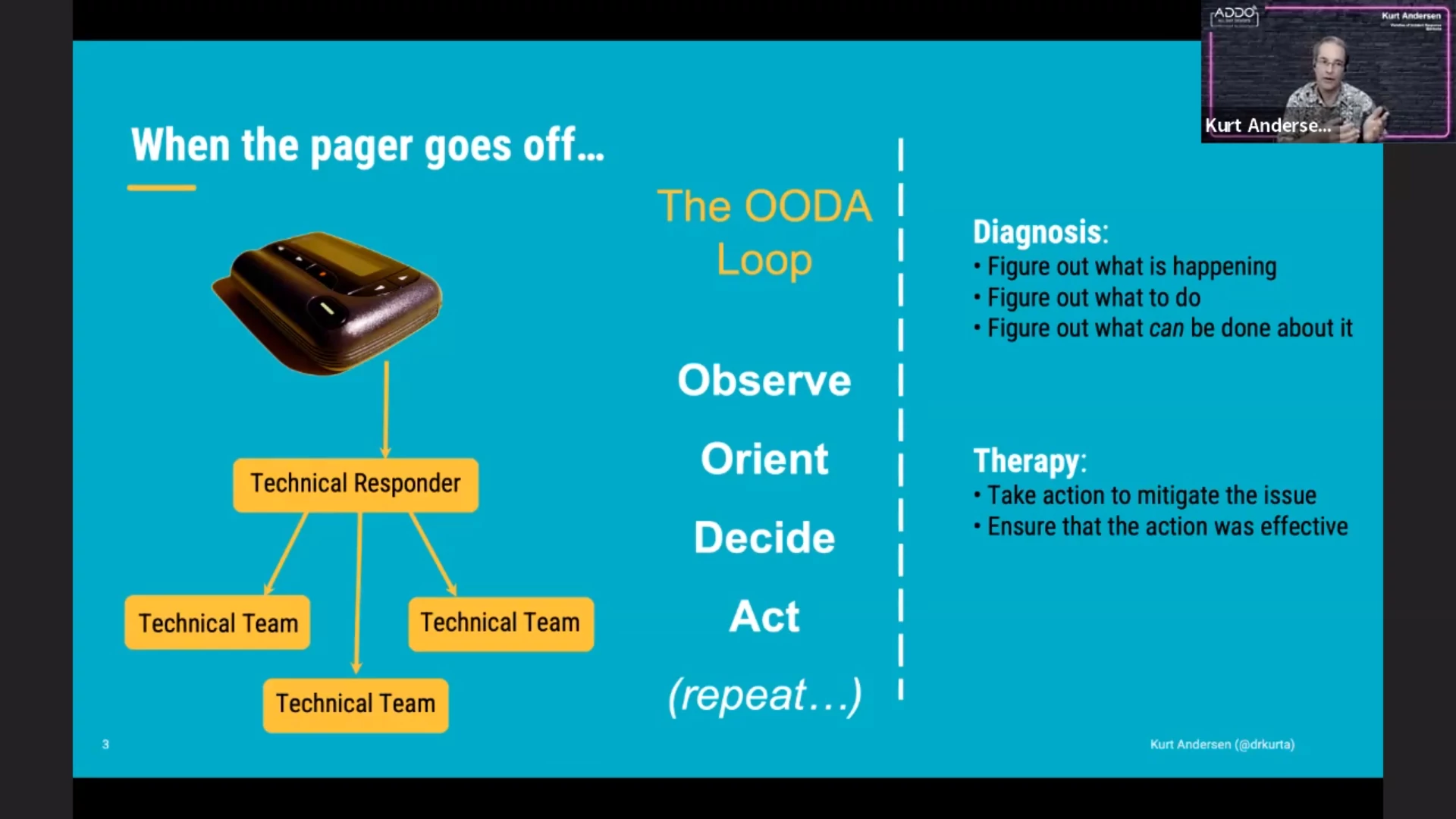
No matter how reliable our systems are, they are never 100% — an incident can
always happen. When the pager goes off, the first step is to recruit a response
team. This team can then observe what is going on. They need to figure out what
this means (orient themselves) and decide what to do. And finally they can act
to resolve the problem. (The OODA loop.)
Getting the right people involved can be hard for the technical responder; they
themselves might want to dive into the technical stuff first. This is where the
“incident commander” role comes in. The incident responder will recruit the team
to get the right people involved, coordinate who does what and handle
communication with people outside of the response team. (The latter can also be
handled by a dedicated “comms lead” if needed.)
But how does the incident commander get involved?
A fairly standard approach for an on-call system will be to have a tiered model:
tier 1 (NOC), tier 2 (people generally familiar with the system) and tier 3 (the
experts of the system having the issue). The problem with this model: where does
the incident commander come from? Tier 1? If so, can the incident commander
follow through if the issue is handed over to the next tier?
Another model (“one at a time”): team A gets involved, decides it is not their
responsibility, hands over to team B, which kicks it to team C, etc. Where does
the incident commander come from in this model?
The aforementioned models only work in the simplest cases. They share a few big
problems: handoffs are hard and there is no ownership, which results in loss of
context. To mitigate this, some teams have an “all hands” approach where
everyone is paged and everyone swarms into the incident response. However, most
people on the call (or in the war room) cannot contribute. This leads to a
mentality of “how quickly can I get out of here?”
Yet another approach is an Incident Command System (ICS), which comes from
emergency services. In this approach the alert goes to the incident commander
who then involves the team. While this works in some organizations, in tech it’s
usually a bit too regimented.
The ICS morphed to an “adaptive ICS” where the technical team has more autonomy,
but the incident commander is still involved. This system can be scaled up to
where there’s an “area commander” role which coordinates separate teams (via
their respective incident commanders).
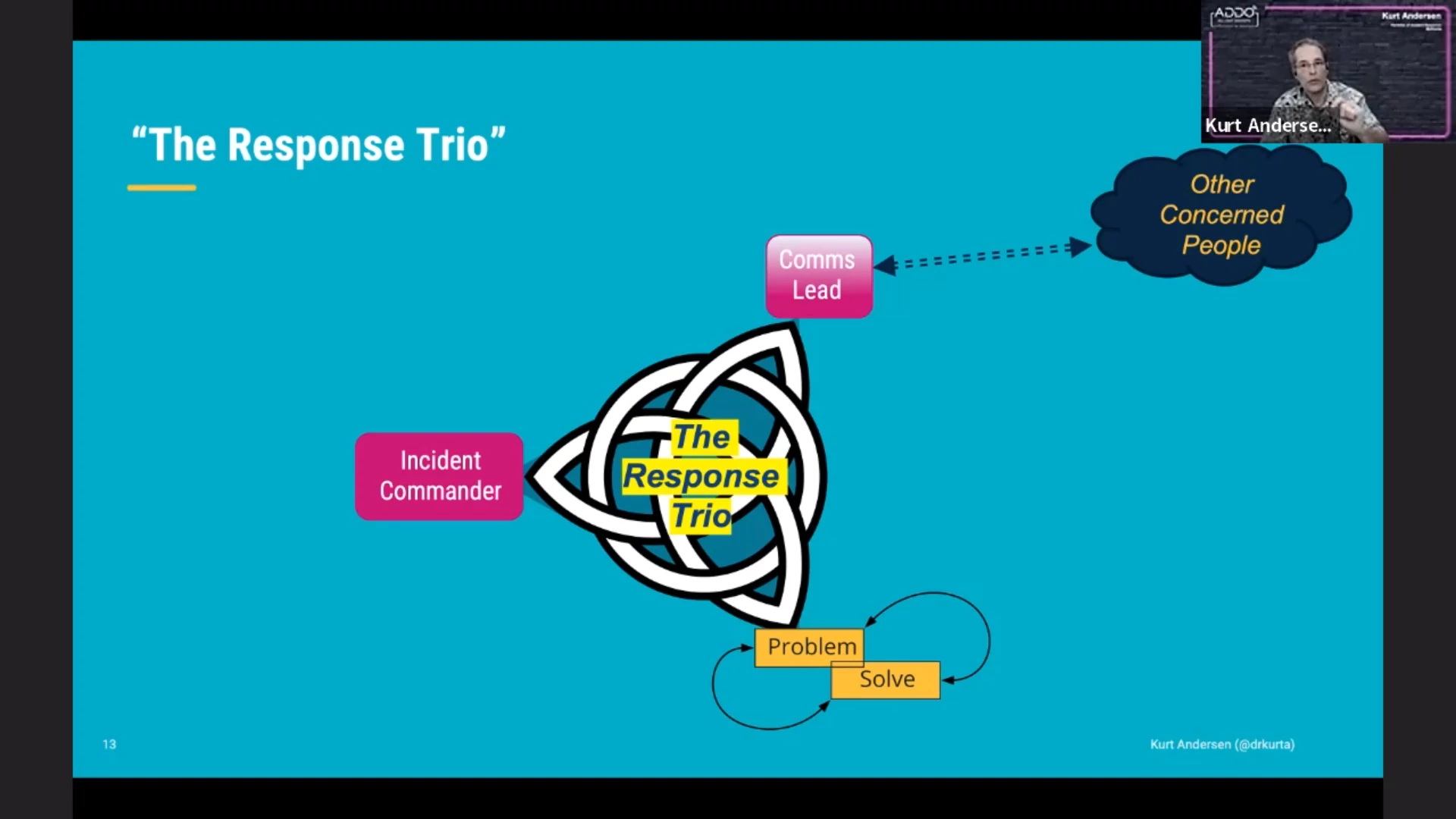
Summarizing the roles of the parties in the “response trio”:
incident commander: coordination
tech team: nitty-gritty to solve the problem
comms lead: maintain contact with stakeholders
Each role will perform their own OODA loop from their own perspective.
But we started the story in the middle. We need to get back to the beginning and
ask the question “why is the pager making noise?” Perhaps the first question one
should ask is: “is this something actionable?” If it is not or if it is something
you can handle in the morning, perhaps you do not have to respond in the middle
of the night.
Cut down the noise and focus on the signal.
The E Stands for Enablement - Modern SRE at PagerDuty — Paula Thrasher
PagerDuty had an idea what SRE meant: they were enablers. You can hit them up on
Slack and they help you out with a problem. Having an SRE team initially reduced
the total minutes in incident in a year. But when PagerDuty grew further, the
number went up again. Oops.
The “get well” project required teams to have the following:
Fast rollbacks: all rollbacks have to happen within 5 minutes. The SRE team
provided guidelines to help teams achieve this.
Canary deploys: teams must test changes (canary) first. The SRE team enabled
this via tooling.
Product limits: reasonable limits. The SRE team made this possible via
telemetry and monitoring.
Results:
Lower number of minutes in major incident
Lower mean time to resolve
More “incidents averted”: four minor incidents were resolved before they
caused real harm.
Important elements that made this “get well” project possible:
Clear, measurable goals
Enabled by tools and templates
Gave teams a path to do it
Experts were available to coach
The teams owned the implementation themselves
The teams were held accountable
PagerDuty used Backstage as an internal “one stop shop”
developer portal with documentation and insights. It also integrates with the
development systems.
]]><![CDATA[Pulling Docker images via a SOCKS5 proxy]]>https://markvanlent.dev/2022/05/10/pulling-docker-images-via-a-socks5-proxy/2022-05-10T20:14:56Z2022-05-10T00:00:00ZThis post describes how you can work around a firewall to pull Docker images
from a server that you do not have direct access to, using a SOCKS5 proxy.
Why would you want to do this?
Let us assume you are in a corporate environment. And let us further assume that
you want to pull Docker images from a registry that you do not have direct
access to from that corporate environment, for instance because the registry is
running on a non-standard port and is thus blocked by a firewall.
So for instance the following does not work for you:
docker pull registry.example.com:5678/image
Now let’s make a few more assumptions:
You have got SSH access to a machine outside of the corporate environment.
You are not violating any policy by bypassing the firewall, or have permission
to do so.
Workaround
To work around the issue, you can do the following:
Connect to a machine over SSH
Tunnel your docker pull command via that SSH connection.
Setting up the SOCKS5 proxy connection
You are going to use the -D option in your SSH command. This allocates a
socket listing on a port. Connections made to this port are forwarded over the
(secure) channel.
For example, if you can use host 172.31.10.5 as a proxy, the command would look
like this:
ssh -D 8080 172.31.10.5
Every connection to port 8080 on localhost is proxied via host 172.31.10.5.
Configure Docker
To make Docker use the proxy, you will have to configure dockerd. One way to do
this is to create the file /etc/systemd/system/docker.service.d/proxy.conf
with the following content:
(You most likely do not even need the HTTP_PROXY line, but it also doesn’t
hurt. ;-) )
Once this file is in place, you need to restart the Docker service:
systemctl daemon-reload
systemctl restart docker
When you run the following command again, the traffic is tunneled via your proxy.
docker pull registry.example.com:5678/image
Voilà, the firewall is bypassed and you can now pull your Docker image.
]]><![CDATA[Migrating to Hugo]]>https://markvanlent.dev/2021/12/10/migrating-to-hugo/2021-12-10T12:24:36Z2021-12-10T00:00:00ZOnce again have I rebuilt this website with a completely different technology
stack. This post dives into some of the details.
To be honest I’ve written this post mostly for myself. I’ve edited all my posts
(see below) and it was fun to read about the (major) changes I made to this site
over the years and rediscover what I did and why I did it.
So here’s another chapter…
Bye bye Acrylamid, hello Hugo!
I last changed the technology stack that generates this website in 2012 when I
migrated to Acrylamid. I’ve been happy
with that choice for years but Acrylamid has been unmaintained since 2016 and I
wanted to use something else.
I shopped around for static site generators that allow me to write my posts in
Markdown. After looking at a couple of options I decided to pick
Hugo. I like it because:
There are quite some themes available (at the moment
there are 285 listed with the tag “blog” for example)
Process
At first I started out with one of the themes
(Noteworthy) to get
up-and-running quickly. Later on in the process I started building my own theme,
using bits and pieces from Noteworthy. Funny thing is that I ended up with
something looking very similar to what I had for my Acrylamid site.
I chose to not render any raw HTML code in my Markdown. To compensate I have
created a couple of custom Hugo shortcodes
to be able to e.g. use the <blockquote> element with a citation attribute or
create tables. On the one hand it removes some flexibility you have when you can
write raw HTML, on the other hand it forces me to do things more consistently by
using the shortcodes.
Having to replace the raw HTML plus fix lots of broken links, led to the decision
to review each and every blog post I have written here. There are only about 150
of them, so that didn’t seem like a massive job… In the end it took me way
more time than I expected to go through them all.
It was also fun to read the old posts, like the ones I wrote during
my first Plone conference in 2008. And when I read the
open tabs post I made in 2018 I rediscovered a book I wanted
to read. And although I still haven’t actually read Dark
Matter yet, I have
purchased it and uploaded it to my e-reader.
While working on this version of my website I took the advice given by Rain Leander in her
2021 devopsdays Amsterdam talk:
Playing is instrumental to life. No one can tell you how to play. Do
what is fun for you. And when it stops being fun, just stop doing it.
As a result I alternated between editing old posts, working on the theme,
picking fonts, etc. Or not work on it at all if I didn’t feel like it. This
meant I could have finished this sooner, but that’s okay—it’s only a hobby
project.
Theme
As I’ve said: I started out with an existing theme, but ended up with creating
my own theme. Unfortunately I do not have a clean separation between content and
theme at the moment. I might want to improve this in the future, but it is the
reason why I haven’t made a separate Git repository for the theme now: the
project and theme are too tightly coupled.
The way this new site looks is only slightly different from
what it looked like before. Under the hood I’m using newer CSS layout options:
grids and
flexbox.
I cannot call myself an expert on these topics, but it sure was fun to play
around with them.
I also wanted to jump on the variable
font
train. I liked the idea of only having to include a single font which can then
be used in all kind of different weights. However I was not able to
get it down to an acceptable size. The closest I got was still about 5 times the
size of a regular font, which means a much bigger chunk of data to download for
the visitors of this site.
As a result I’m sticking to standard fonts for now. I picked the fonts I liked
on Google Fonts and used
google-webfonts-helper to
download the files needed to self-host them. My choice at this moment:
Although I never had complaints about the speed of Acrylamid in the past, Hugo
is quite a bit faster. This became obvious when I was writing my
notes for All Day DevsOps. I had been five
months since I had written something here, but in the meanwhile I had been
working with Hugo to edit my old posts and create the theme. And I had gotten
used to LiveReload
which in practice meant that a page had already reloaded in my web browser in
the time it took to switch from my editor to my browser.
The live reload alone makes the process feel much snappier, but I was curious
about the actual difference in build times between Acrylamid and Hugo. So I
decided to test the two use cases that are most important for me since this is
what I do most of the time:
A complete rebuild, e.g. to deploy to the live environment (without artifacts from
experiments/drafts, etc)
When I create/edit a post I have Acrylamid/Hugo watch the files and rebuild
the site on change.
I ran these scenarios three times and took the shortest run for both tools.
Action
Acrylamid (ms)
Hugo (ms)
Complete rebuild
1497
397
Watch
1300
95
This confirms what I had already suspected: Hugo takes only a fraction of the
time Acrylamid needs when rebuilding the site after I change a post (the 2nd use
case). Combined with the live reload this makes for a big difference in my
workflow.
New domain
For this version of this site I also switched to a new domain. I got the
vlent.nl domain in 2003 and used it for my website ever since. Now, 18 years
later, I’ve decided to start using a different domain for this site:
markvanlent.dev.
Although this frees up the vlent.nl domain for other stuff in the future, I
have setup a redirect for (I think) all the URLs I was
using. At first I wasn’t sure if it would be worth the effort, but after going
through 13 years of blog posts I can tell you that it is really nice if old URLs
still exist or at least redirect to a new location for the content.
New hosting
I’ve been managing my own virtual private servers for this site since
2013 and it was fun. It offered me a lot
of control: deployment,
web server,
TLS configuration, et cetera—I was all up to
me. And that’s also the downside: there was only 1 person maintaining it: me. It
doesn’t cost me that much time, but it’s something I have to take care of
nonetheless. And if e.g. a new version of Docker
no longer proxies IPv6 requests by default,
it’s also up to me to (a) detect the update broke something and (b) solve it.
Because maintaining a VPS no longer brings me joy, and I’ve heard good things
about Netlify, I thought this was a good moment to
try them out. Especially now that I’m using Hugo, one of the common build
configurations,
switching to Netlify quite simple.
Future
I might want to tweak the theme in the future or see if I can have a more clear
separation between the theme and the content. But for the moment I’m happy and
enjoying the fact that this project is finished.
]]><![CDATA[All Day DevOps 2021]]>https://markvanlent.dev/2021/10/28/all-day-devops-2021/2021-12-09T21:14:34Z2021-10-28T00:00:00ZAll Day DevOps, the free online DevOps
conference that goes on for 24 hours, was held for the 6th time today. With a
total of 180 speakers spread over 6 tracks, there’s even more content than the
last time I attended. These are the notes I
took during the day.
Derek Weeks opening the day for All Day DevOps
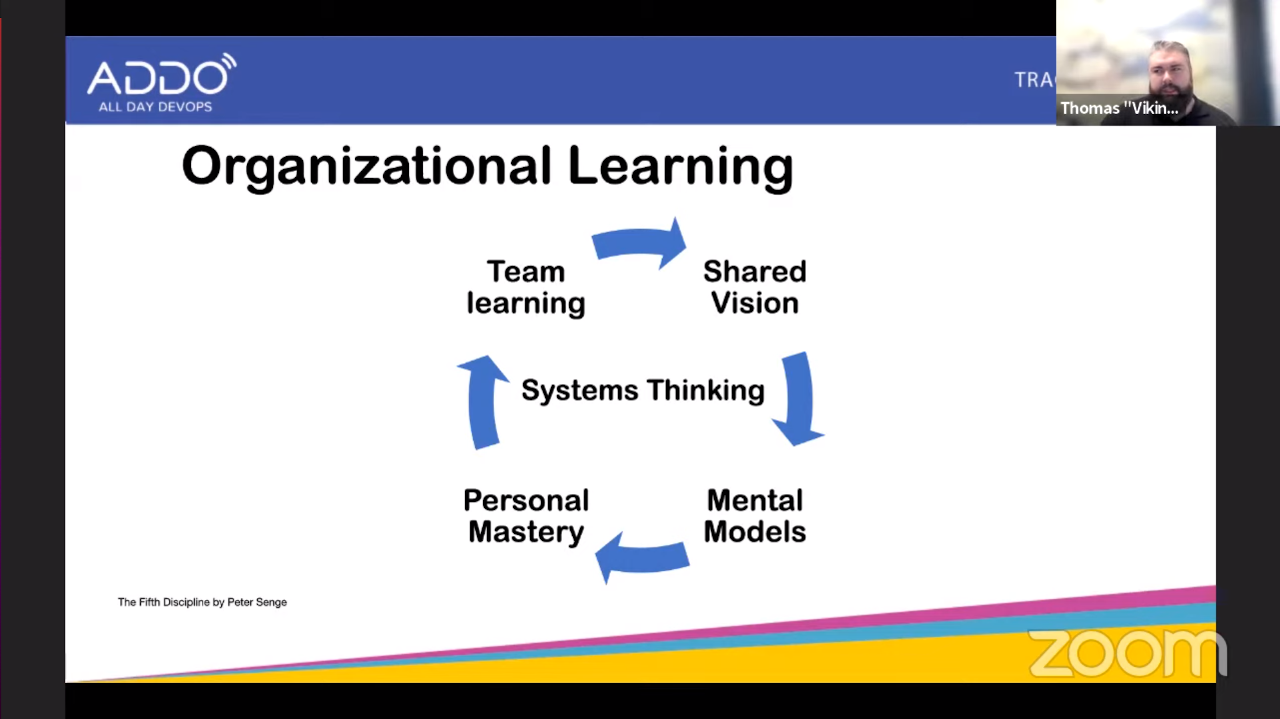
Keynote: CAMS Then and Now and the Path Forward — Thomas “VikingOps” Krag
When people think about DevOps, they think of CAMS, which stands for:
Culture
Automation
Measurement
Sharing
The term CAMS was formalized by John Willis and he wrote down his idea in the
article What Devops Means to Me.
This talk will focus on the most important aspect: culture, and specifically
organizational learning.
Culture
Culture as described by Simon Sinek:
A group of people with a common set of values and beliefs. When we’re
surrounded by people who believe what we believe something remarkable happens.
Trust emerges.
Have people play the game not just because of the rules, but because they feel
responsible for the game.
Mental Models
Breaking your own assumptions and how they can influence your actions. You
need to self-reflect on your own beliefs.
Personal Mastery
This is about owning yourself, learning and achieving your personal goals. And
to do the latter you first need to define what is important for yourself.
Team learning
Effective teamwork leads to results that persons cannot achieve on their own.
And individuals working as a team can learn faster than they would by themselves.
Systems Thinking
Looking into patterns that emerge inside your organization from a
holistic viewpoint instead of just looking at your own team.
Automation
Automation is about automating the right things. You don’t want to do it just to
automate things, but it has to fit in the system. So you have to start with
culture before you think about automation. The ultimate goal is
GitOps where everything happens via a pull request.
Measurement
Measurement started out with a focus on the tooling. But
measuring how you work is as important as measuring your infrastructure.
deployment frequency (how often do you release to production)
lead time for changes (the amount of time for a change to get into production)
time to restore service (how long does it take to recover from a failure in
production)
change failure rate (the percentage of deployments causing a failure in
production)
Sharing
Share how you are doing (in) DevOps. This is how we ended up here now.
Share how you are improving your own organization. But also share information
within your organization: documentation, videos, presentations,
open spaces,
lean coffee sessions
Working on your culture is as important as doing your actual work.
So what’s next? CAMS is still as applicable as 10 years ago. It has always been
important, but it was only put into words in 2010. We need to continue sharing
to get the full value out of it.
Gamification of Chaos Testing — Bram Vogelaar
We think of Usain Bolt as the record
breaking athlete, but he’s also the person that worked really hard to get there.
It takes a lot of time and effort to become good at something. Pilots and firemen
spend most of their time training and not doing what you expect them to do; just
to make sure they perform well under pressure. Also note that pilots use a lot
of checklists to prevent mistakes.
We should do the same: train for when our platform is in an error state. We
should not just be able to detect it, but also solve the problem.
Chaos engineering is the discipline of experimenting on a distributed system
in order to build confidence in the system’s capability to
withstand turbulent conditions in production. This
practice started at Netflix with Chaos Monkey.
We need to become comfortable with experimenting. Have game day exercises and
analyze what happened, to improve your training. Do not just focus on the result
of the exercise itself, but also ask questions like “was it the right
experiment?”
Now that we use containers, add sidecar containers with tools to get metrics or
detect errors. Or to do chaos engineering e.g. with
Toxiproxy.
Since checklists are boring, we can use gamification to spice things up.
Celebrate failure, and learn from it!
Living in the year 3000: breaking production on purpose on Saturdays and have
the system remedy the problem itself.
Convince management that failure is normal and expected behaviour. Promising
100% uptime is not realistic. Large, complex systems will always be in a
(somewhat) degraded state.
Let engineers be scientists to deal with this complex environment. Give them
training, allow them to do tests (experiments), which results in having valid
monitoring that lead to actionable alerts. Get the engineers in a state where
they are comfortable with failures.
Watch Your Wallet! Cost Optimizations in AWS — Renato Losio
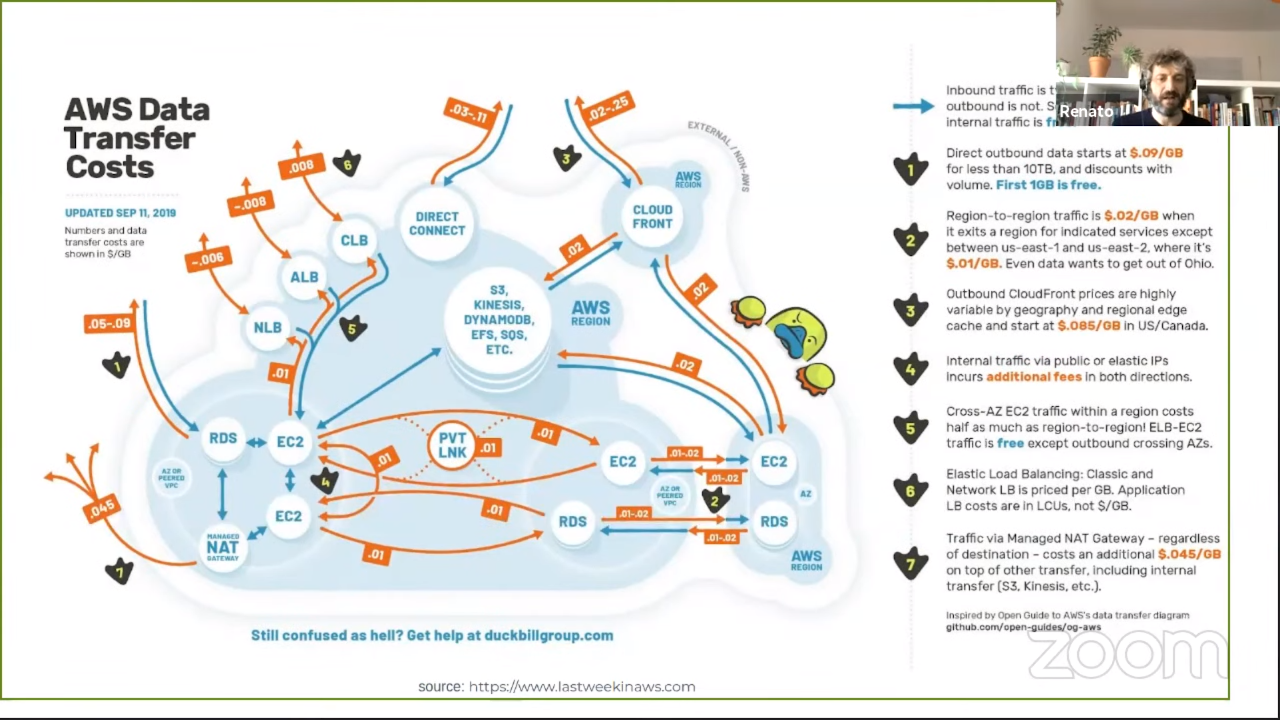
Each AWS service has it’s own price components. It’s a complex subject. Even a
simple service like a load balancer has multiple components. It looks simple
with the “$0.008 per LCU-hour” price tag, but now you have to figure out what an
LCU-hour is. Then you learn it has four dimensions that are measured: number of
new connections per second, active connections, processed bytes and rule
evaluations. Good luck predicting the costs.
This presentation only sticks to the basics since cost optimization it such a
big topic.
To start to manage/reduce your costs, you need to enable billing and costs for
your DevOps team. If you cannot measure your costs, you cannot manage it. Note
that you do not need an excessive amount of tags for cost management. First you
need to figure out what you are going to change and how it’s going to affect the
bill for your company.
When savings can be measured, they can be recognized, and cost efficiency
projects become exciting opportunities. As of early 2021, the most viewed
dashboard at Airbnb is a dashboard of AWS costs.
—Anna Matlin, Airbnb
What patterns can we avoid? In most organizations, the most expensive parts of your
bill will be:
Compute
Storage
Data transfer
So we will dive into these subjects.
Compute
Tips to reduce costs:
Avoid fixed IP addresses where possible. This is not so much about the costs
of the IP address itself, but mostly because architectures that require a
fixed IP tend to be complex and more expensive.
Use Graviton (ARM) instances. They have a better price to performance ratio.
You can also migrate managed services (RDS, Lambda functions) to Graviton.
Check out Lightsail. It’s less flexible than using EC2 instances, but cheaper.
Data transfer
We usually forget to take data transfer costs into account upfront. It’s also a
complex subject and there are a lot of considerations to make.
Tips:
Multi AZ is always good, but are 3 zones always better than 2 zones?
Multi region is easy to do nowadays, but expensive with regard to data
transfer. Ask yourself if you really need it.
If you want to use multiple cloud providers always think about the data
transfer costs. Perhaps the storage costs are lower at provider X, but if you
have to transfer data, you’ll probably pay an egress cost.
Using a CDN (CloudFront) might be cheaper than paying for the egress data
transfer otherwise.
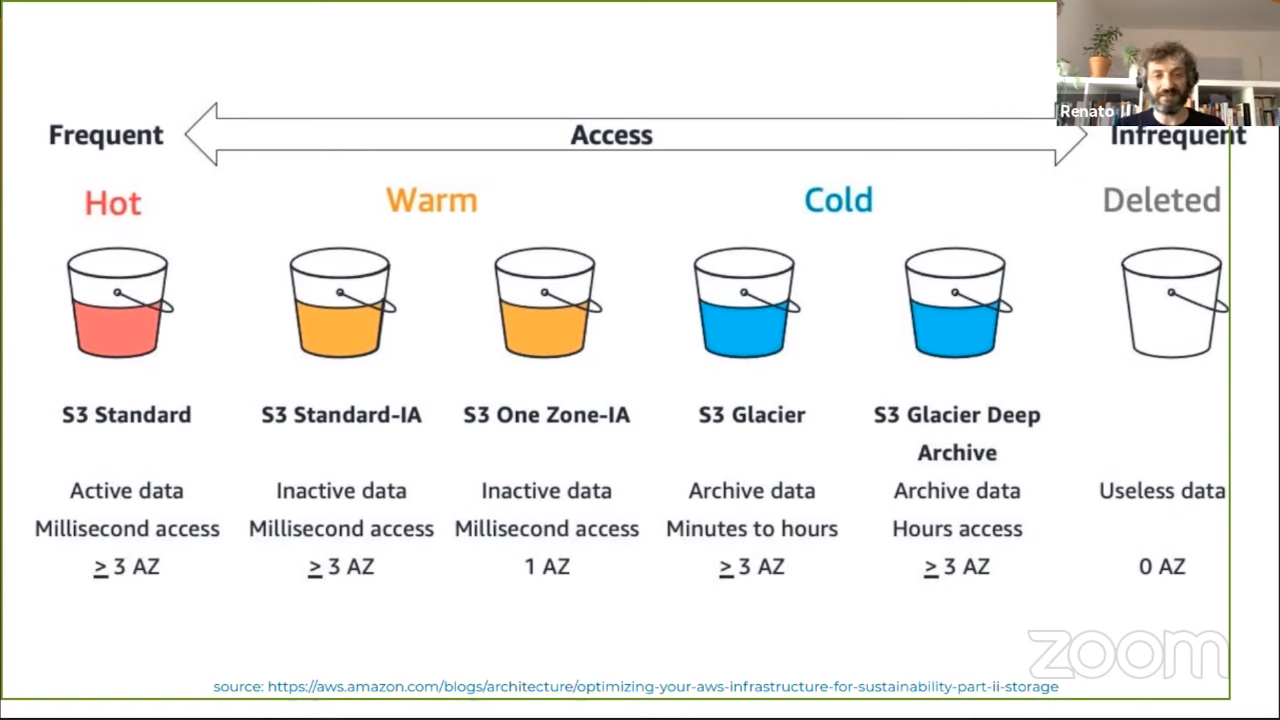
Storage
Initially it was simple: there were only two storage classes. Currently there
are 6 different classes with their own prices and characteristics.
The best option is to use lifecycle rules to move data between different
classes. Note that you in a lifecycle policy you cannot filter the objects based
on an extension (e.g. *.jpg) but instead you need to think “from left to
right.” So you need to think upfront about the prefixes you are going to want to
use in your bucket.
Managed services can offer you automatic and manual backups, which can be great.
But what is the cost of that? Check how much retention you need for example.
With regard to EBS: for most use cases gp3 is better and cheaper than gp2
(except for very large volumes). Note that you can change the EBS volume type
without stopping the machine. In most cases you can have a 20% cost saving
without affecting your performance.
AWS changes quickly
After each AWS re:Invent, your deployment is probably outdated with regard to cost
optimizations. Examples:
Use gp3 instead of gp2 for your EBS volumes.
The instance type m6 might be more interesting than the m5 or m4 you may
currently be using.
Dublin was the cheapest region in Europe, but for most things Stockholm is
cheaper than Dublin at the moment.
So keep up to date with the offerings.
Keynote: Call for Code with The Linux Foundation: Contributing to Tech-for-Good Even if You’re Not Techincal — Daniel Krook and Demi Ajayi
Call for Code is a multi year program launched in 2018 to address humanitarian
issues and help bridge potential solutions. Last year the global challenge was
around climate change and a track was added for the social and business impact
of the COVID-19 pandemic.
It’s not just about generating ideas to take on the issues. It should
eventually also lead to an adopted open source solution that is sustainable.
The key takeaway for this session is to make us help improve how the projects do
DevOps. The goal is to ensure that everyone can contribute to the projects, can do so
with confidence and the projects can be deployed with speed.
The Call for Code for Racial Justice open source projects are categorised in three pillars:
Demi talked about each of these projects in the program and their tech stacks. You
can read more about them on the
Call for Code for Radical Justice section
on the IBM developer site.
Daniel in turn talked about other Call for Code projects:
Even if you cannot code, there are numerous ways you can contribute, e.g.
conducting user research, write/review documentation, do design work, advocacy
like speaking at conferences.
There are multiple ways to get involved:
Via the virtual community (join slack, join events)
Teach this new definition to everyone involved with your project (developers,
testers, product managers, executives, etc)
Create a “DevSecOps” swear jar ;-)
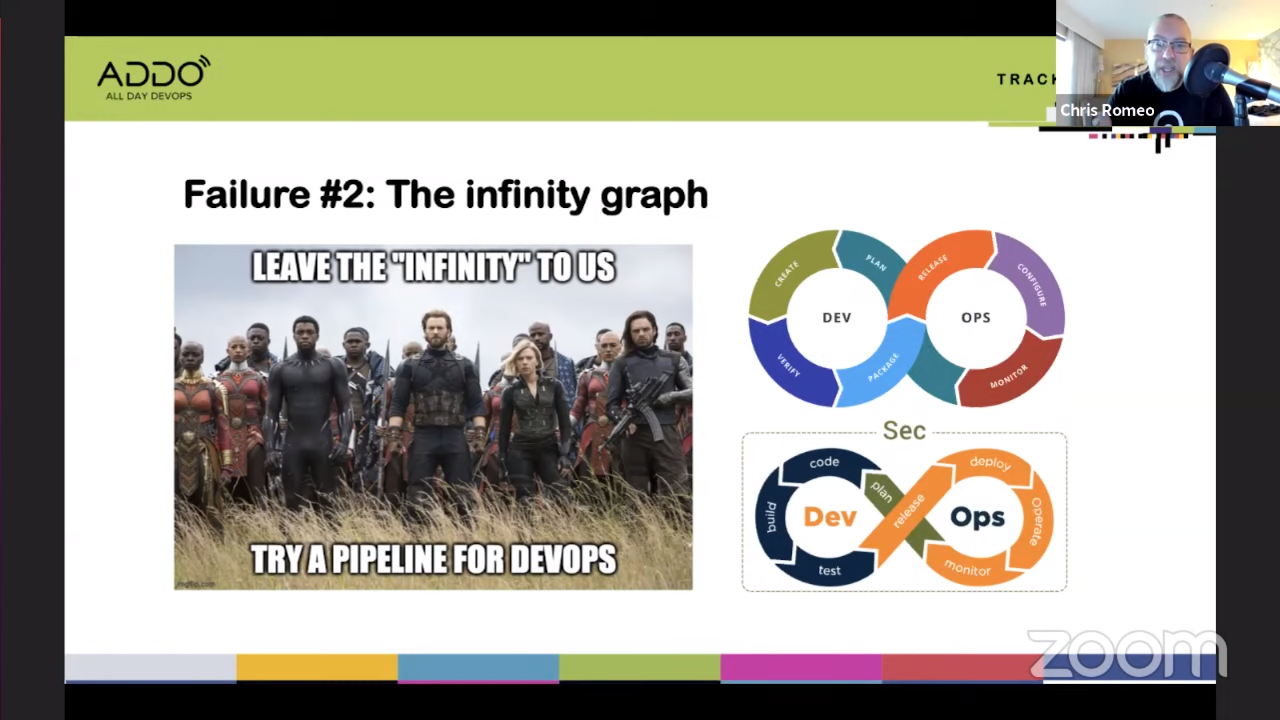
#2 The infinity graph
The problem is that nothing ever gets done with this infinity graph. It’s not an
accurate representation.
The solution is to talk about pipelines instead and integrating security into
them. Code review should include security, vulnerability scanning should be part
of the pipeline, etc. Ban the infinity graph.
#3 Security as a special team
Creating a specific security team is the opposite of what DevOps is about. It’s about
working together. Security isn’t a specialty, it is the responsibility of
everybody. This requires knowledge and expertise.
The other way around is also true: teach security people to code. They don’t
have to become great coders, but it would be nice if they can review code and
make suggestions to make things more secure.
#4 Vendor defined DevOps
Sometimes we let vendors define what DevOps and security are for us, via the
products that they offer. It would be better to find the best of breed outside
of the offering of cloud provider. Take a vendor independent approach and
determine what DevOps means to you.
#5 Big company envy
Looking at the big companies can be discouraging. You most likely have not
invested the same time in it as e.g. Netflix, Etsy, etc. have. So while you
won’t be at the same level, don’t see this as an excuse to give up. Do the
DevOps that you do. Don’t fixate on the top of the class. Get on that path and
make incremental progress.
But keep it simple! Start with a small subset of security tools. Everybody
related to your project should be able to explain the build pipeline. Don’t try
to solve all problems immediately. Take a phased approach.
#7 Security as gatekeeper
Security might want to slow down the pipeline and act as a gatekeeper. Don’t say
“no,” but “yes, if…” For example: “yes, that would be a great feature if you
enable multifactor authentication.”
Practice empathy. Both security people for developers, but also the other way
around.
#8 Noisy security tools
You buy a tool and enable every option to “get your money’s worth.” The result
is 10,000 JIRA tickets of things that need to be fixed. This does not help.
It would be better to tune the tools and don’t waste time with security findings
that do not matter.
Start with a minimal policy focussing on the largest issue. Developers will then
start to trust the tool and then you can slowly increase the policy.
#9 Lack of threat modelling
You scanning tools cannot find business logic flaws; there’s no pattern to it.
Perform threat modelling outside of the pipeline. It should be done when new
feature assignments go out.
#10 Vulnerable code in the wild
There are lots of vulnerabilities in open source software; this is a supply
chain problem.
To improve this: embed software composition analysis (SCA) in all your
pipelines. Set the SCA policy to fail when a vulnerability is detected. If you
filter out a vulnerability (e.g. because there’s no fix yet), make sure the
filter will not be active forever.
Successes
The 10 DevOps successes we can distil from the failures above:
Just call it DevOps
Pipelines
Security for everyone
Embrace your DevOps
Be content with your DevOps
Simple and staged pipeline
Security as trusted partner
Tuned and valuable security tools
Threat modelling for everyone
Breaking the build for vulnerabilities
Key takeaways
Hopefully the real impact of DevOps (when looking back 50 years from now) is
going to be security culture related.
Some of the failures were outside of your control, but you can change them.
Everybody has to code, choose your DevOps, keep it simple, lower the
noise, add the best practices we discussed, do some threat modelling, break
the build for vulnerabilities.
Embrace and laugh at the failures.
Keynote: Managing Risk with Service Level Objectives and Chaos Engineering — Liz Fong-Jones
Besides being a principal developer advocate at Honeycomb, Liz is also a member
of the platform on-call rotation. Honeycomb deploys with confidence up to 14
times a day, every day of the week—so also on Fridays. How do they manage to
(mostly) meet their Service Level Objectives (SLOs) while also scaling out their
user traffic?
Their confidence recipe:
Quantify the amount of reliability.
Be able to identify risk areas that might prevent them from fulfilling their
targets.
Test to verify that the assumptions about the systems are correct.
Respond to that feedback to address the problems found via those experiments
or though natural outages.
How to measure reliability?
You need to know how broken is “too broken.” You don’t have to alert on all
problems when working at scale. You need to measure success of the service and
define SLOs. These are a way to measure and quantify your reliability.
Honeycomb’s jobs is to reliably ingest telemetry, index it, store it safely and
let people query it in near-real-time. Honeycomb’s SLOs measure the things
that their customers care about.
For example, they have set an SLO that the homepage needs to load quickly
(within a few hundred milliseconds) in 99.9% of the times. User queries need to
be run successful “only” 99% of the time and are allowed to take up to 10 seconds.
On the other hand: ingestion needs to succeed in 99.99% of the time since they
only have one shot at it.
Services are not just 100% down or 100% up (most of the time).
These metrics help Honeycomb make decisions about reliability and product
velocity. If the service is down too much, they need to invest in reliability
(since having features that cannot be used does not add value). On the other
hand: if they exceed the SLO, they can move faster.
Recipe for shipping reliably and quickly
Practices used by Honeycomb:
Code is instrumented. Think beforehand what a success or failure in
production would look like.
Functional and visual testing using libraries that create snapshots.
The design for feature flag deployment (only making a feature available to a
small percentage of users initially).
Practice automated integration plus human review. (There’s an SLO for how
long the tests are allowed to take. Code reviews are high priority tasks
since you are blocking someone else by not reviewing their code.)
The main branch is safe to release any time.
Automatically roll out the changes.
After the deployment the engineers have to observe what is happening with
their code in production. Only after they confirm that everything is okay,
they can go home. So you are free to deploy on Friday at 19:30 as long as you
are willing to stick around until your code is deployed and you have confirmed
it is not causing issues.
For infrastructure Honeycomb also use infrastructure as code practices:
They can use CI and feature flags for their infrastructure.
They can automatically provision fleets if needed.
They can automatically quarantine certain paths to keep the main fleet from
crashing or do performance profiling.
Chaos Engineering
Left-over error budget is used for chaos engineering experiments. This is
something where you go test a hypothesis. You need to control the percentage of
users affected by it and be able to revert the impact you are causing.
Chaos engineering is engineering. It’s not pure chaos.
This works well for stateless things, but how does it work for stateful things?
In the case of the Honeycomb infrastructure, they make sure to only restart one
server or service at a time. They do not introduce too much chaos to reduce the
likelihood that something goes catastrophically wrong.
Two reasons why you will want to do these experiments at 3 PM and not at 3 AM:
You want to test at peak traffic instead of low traffic, since the latter
could give you a false sense of security in situations when everything may
still look normal even though this would have been a problem in a high traffic
situation.
When doing things in the afternoon, there are more people available to deal
with something than there would be in the middle of the night.
With the experiments they measure if they had an impact on the customer
experience. If they cause a change, does the telemetry reflect this? (Is the
node indeed reported as being offline, for example?) When you fix things, you
need to repeat the experiment and make sure the change indeed fixed the issue.
When you burn the error budget, the SRE book
states that you should freeze deploys. Liz disagrees. If you freeze deploys, but
continue with feature development, the risk of the next deployment only
increases. Instead, Liz advocates for using the team’s time to work on
reliability (i.e. change the nature of the work instead of stopping work).
Fast and reliable: pick both!
You don’t have to pick between fast and reliable. In a lot of ways fast is
reliable. If you exercise your delivery pipelines every hour of every day,
stopping becomes the anomaly instead of deploying.
Takeaways
By designing the delivery pipeline for reliability, Honeycomb can meet their
SLOs.
Feature flag can reduce blast radius, and keep you within your SLO.
And when they cannot: there are other ways to mitigate the risks.
By discovering risks at 3 PM and not 3 AM, you improve the customer experience
since the system is more resilient.
If something does go catastrophically wrong, remember that the SLO is a
guideline not a rule. SLOs are for managing predictable-ish unknown-unknowns
and not things that are completely outside of your control.
We are all part of sociotechnical systems. Customers, engineers and stakeholders alike.
Outages or failed experiments are learning opportunities, not reasons to fire someone.
SLOs are an opportunity to have discussions about trade-offs between stability and speed.
DevOps is about talking to each other and talking to our customers.
Common Pitfalls of Infrastructure as Code (And how to avoid them!) — Tim Davis
We start with the basics: what is Infrastructure as Code (IaC)? With the advent
of cloud providers, you no longer use hardware, but a UI to stand up
infrastructure. This led to shadow IT
since developers ran off with a credit card to provision what they needed
themselves, instead of using slow, internal IT systems.
Developers however rather write code and use developer methodologies than click
through a UI. This is where IaC started. With it you can create and manage
infrastructure by writing code.
What are he pitfalls? The bad news: you get all the pitfalls of infrastructure
and all the pitfalls of code. But you’ve probably already got a lot of
experience with those issues and teams to handle them. You just use a different
methodology.
The first pitfall is not fostering the communication between the groups that
have experience and tools.
Infrastructure pitfalls
Which framework/tool do you pick? There are basically two categories:
multi-cloud or cloud agnostic tools on the one hand (like
Terraform and Pulumi)
and cloud specific tools on the other (like
CloudFormation). Note that for example
with Terraform and Pulumi you still have to rewrite code when switching from one
cloud provider to another, but at least the tool is familiar.
Security is a huge thing. You still need to know how to design your VPC, IAM
policies, security policies, etc. You still need to communicate with all the
teams that have the experience. It’s not just Dev and Ops. With tools like
Terrascan and
Checkov you can shift-left the security aspect
instead of trying to bolt it on afterwards.
Code pitfalls
The biggest thing issue is with default values. If you use the UI, there are a
lot of boxes that may be blank or have stuff in them. Some of the boxes can be
left blank, for some you need to specify what you want. The UI is going to
yell at you; if you use IaC things may be less in your face.
You don’t want to deploy something with an open policy.
Open Policy Agent can really help you to make sure you
stay within your allowed parameters. For instance you can write a policy to make
sure you are only use a specific region, don’t deploy an open S3 bucket or that
you only use certain sizes of EC2 instances.
If you hard code certain values in Terraform or other IaC tools, you might need
to copy/paste a lot of code if you want to create e.g. a test, acceptance and
production environment. To mitigate these DRY (don’t repeat
yourself) issues you can
for instance use
Terraform modules or
Terragrunt.
State size can become a problem. If you want to, you can put all of your
infrastructure in the same state file (which is where your tool stores the state
of the infrastructure). However it means the tool will have to check all
resources in the state file to detect if it needs to do something. To mitigate
this, you can again use Terraform modules. It helps with performance and makes
the codebase more manageable.
Wrap-up
The conference is still ongoing while I publish this post. However, this is it
for me for All Day DevOps for this year. I learned new things and got inspired.
Thanks to the organizers, moderators and speakers for hosting another great
event.
]]><![CDATA[Devopsdays oNLine 2021]]>https://markvanlent.dev/2021/06/29/devopsdays-online-2021/2021-11-10T20:39:28Z2021-06-29T00:00:00ZSince COVID-19 is still
around, devopsdays Amsterdam was an online event again. These are the notes I
took while watching the talks.
How cognitive biases and ranking can foster an ineffective DevOps culture — Kenny Baas & Evelyn van Kelle
In practice, not all team members are treated equally although we might think
they are.
How to make sure everyone said what has to be said?
In each team ranking takes place. It determines who takes the lead, who
expresses an opinion, etc.
We need to make sure ranking is made explicit. Your job title or position in the
org chart is explicit ranking. But things like your gender, skin colour and level
of charisma are part of the implicit ranking.
The result of this ranking can be a situation like this: a woman on the team
just explained something on a certain topic, but questions about it are addressed
to the white man in the team.
We all have a list of traits we associate with higher rank. So if someone ticks
more of those boxes, they are seen as higher in rank. You can also rank yourself
lower compared to others. As a result you might not express your opinion because
someone you regard as having a higher rank said something that conflicts with
what you wanted to say.
The person with the higher rank should be aware of their rank and “share it.”
Ask yourself the question “what don’t I know?” in a discussion. Ask the
question the other (with a lower rank) is afraid to ask.
Own, play and share your rank.
How can we create and include new insights?
We use cognitive bias to make decisions. Usually this helps us, but sometimes it
works against us. What we know hinders us from taking on a new perspective and
it limits us in our thinking. We get stuck in what we know
(functional fixedness).
Be aware of your biases and try to break free from them.
Who makes decisions and how to get everyone onboard with the decision?
Have less “corporate” meetings and more “campfires” where we share ideas and talk
about the why.
There are 4 ways to go into a decision:
Idea
Suggestion
Proposal
Command
If you have a proposal or command, be open about it: “this is what we are going
to do, what does it take to go along with it?” This is better than pretending it
is completely open for discussion.
Getting Started: Embrace Your Inner Child — Rain Leander
Learning to ride a bike when you are older is harder than when you are a child.
This is not so much a physical thing, but we do not want to be embarrassed when
we are older. This goes for everything new we do: we want to be the
best—instantly. However you will fall down and fail. You will make mistakes.
Embrace that, be brave and learn.
Bravery is something you have to develop. It is hard! And it is not a lack of
fear, it is moving forward despite of fear.
The steps to become more brave that worked for Rain:
Embrace vulnerability
Admit you have fear
Do it anyway
When you fall down, get back up
Play!
Playing is instrumental to life. No one can tell you how to play. Do what is fun
for you. And when it stops being fun, just stop doing it. Book time in your
agenda to play, each day! (And napping counts.)
Explore! Some of the things Rains uses to stay curious and explore:
Listen
Ask questions
Avoid assumptions
Listen
Embrace learning as fun
Develop a beginner’s mind
Listen
You are a unicorn. Your experience, your background, your education, etc. makes
you unique.
Be willing to fall down, and get back up. Be brave. Play! Conquer the world.
Prevent Heroism: How to Work Today to Reduce Work Tomorrow — Quintessence Anx
We might be familiar with “the angry sysadmin.” It is the person who is highly
skilled, has lots of knowledge, gets asked all the questions and puts in overwork to get
their own work done. This is basically the description of the character Brent
from the book The Phoenix Project.
Being a Brent-like person is stressful and may result in anger, resentment and
strained relationships. Brent-like persons typically have issues with things
like time management, maintaining focus and
allostatic load (where you’re too tired to
be awake and too stressed to sleep). But there are business implications as well:
diminishing returns, high turnover, reputational damage and financial
performance goes down.
Instead of having—or being—a Brent-like person, we rather want no silos and
no vacuums (the latter is where you, for instance, get no response to
questions).
Steps to get out of this situation and do things different:
Brainstorm the work (every task done during the day, planned or unplanned)
Determine which “stream” each task is in: reactive or proactive
Look for patterns
Switch to “upstream mode” to prevent work in the future (short term/long term
vs permanent/temporary matrix)
Plan and Prioritize work: upstream work is more important
Do the work
Iterate (what works, what does not, what can be improved)
Upstream work is the proactive and preventative work that reduces the need for
reactive, or downstream, work
But how does one measure things? Things to keep in mind:
This talk is a real life case study, focussing on the deployment of the platform
of a customer of Michiel.
There was a pretty long release check list with manual steps. Especially when
under pressure steps were forgotten or done incorrectly. Ideally they released
every two weeks (after each sprint). It took a team 2–3 days of manual work.
Time not spent on features.
To improve this situation, the following goals were set:
Reduce costs by letting people do more valuable work
Faster feedback and ability to do more experiments
For continuous delivery to work, you have to make things small. This is a key
difference between high and low performing teams (see
Accelerate).
Although the platform was a monolith, they deferred splitting it up. If they
would have broken down the monolith into smaller pieces, they would have more
manual steps for each release and made the situation worse. So the strategy was
to automate first and then split.
Phase 1
The teams increased the release cadence. They switched to a weekly release cycle
instead of a release every two weeks (on good weeks). Releasing more often makes
problems visible faster.
The release process was also automated. They created a pipeline to build and
deploy the platform. In this phase there was still a manual step between the
deployment to acceptance and production. They didn’t trust the system enough
yet.
They also made changes in their way of working. The big one: pair programming.
This is superior to code reviews, for example because you also discuss code that
does not get written and you have architecture discussions.
Other changes:
A “do not leave broken windows” mentality. This is from the book
The Pragmatic Programmer)
which states: neglect
accelerates the rot faster than any other factor.
Measure how they were doing in terms of their continuous delivery journey.
The book Measuring Continuous Delivery
has useful information about this.
Phase 2
In the next phase they had a robot press the button to deploy to production.
This required zero downtime deploys. They solved this by doing rolling updates
(a load balancer in front of a couple of backend servers and then upgrade one
server at a time until they are all up-to-date).
Pipeline failures come in all forms, e.g.:
Flaky tests
Timeouts
Network stability issues
External dependencies in tests
If you cannot trust a test, remove it. Otherwise you’ll probably work around it,
which is more dangerous.
This level of automation also meant they treated pipeline failures as priority 1
issues (which warrants extreme feedback to notify people of a broken build:
lights, sounds).
Phases 3
In the third phase they made it faster:
Scale vertically and horizontally
Parallelize tests
The Adjacent Possible: Evolution, Innovation & Catastrophe — Jason Yee
The four cornerstones of resilience:
Monitoring: knowing what to look for
Responding: knowing what to do
Learning: knowing what has happened
Anticipating: knowing what to expect
The term “adjacent possible” comes from biology in the context of evolution.
Evolution requires a chain of changes to happen.
Complex systems usually do not have a single root cause, only contributing
factors. Perhaps there’s an “adjacent possible” of failure. We cannot anticipate
all failures, but perhaps we can explore them.
How do you explore adjacent possible failures?
To move from known knowns to known unknowns, we can use chaos engineering
(thoughtful, planned experiments to improve our understanding of how systems
work (and fail), so that we can improve them). This way we can explore the
known unknowns and these then become the known knowns. From that standpoint,
the original unknown unknowns become the known unknowns.
Scientific process:
Observe (what is normal)
Hypothesize (how do we think it will react to failure)
Experiment (inject failure)
Analyze (what did actually happen)
Share knowledge
Explore the adjacent possible!
Minimal viable presentations — Mark Smalley
There are four important points to take into consideration when creating a
presentation:
Accept that it is not about you
It is the audience’s presentation. What you want to tell might not be what
they want to hear. Kill your darlings.
Anticipate silent questions
These questions are:
Huh? What is he talking about? (Solution: be clear about the self evident stuff)
Really? (Solution: be clear about the evidence)
So? How is this relevant for me? What’s in it for me?
What’s next?
Think of learning objectives
Think about what the audience should know, believe, be able to do and feel after the
presentation.
Dare to choose your ideal audience
Accept that the presentation will not be for the majority of the people
listening.
Mark Smalley applies the advice given in his talk to this talk itself
Engineering Metrics That Matter — Dan Lines
Before we dive in, let’s start with some
KPIs you want to avoid:
Lines of code
Number of commits
Individual stack ranking
Anything with story points
So what do you want to measure? What will improve your process?
Couple pull request size with cycle time (how much time from coding to deployment)
What you’ll see is that bigger PR size takes longer to review and
thus increase cycle time.
Deployment frequency
How often can we get new value into the hands of customers.
Idle time
Waiting for e.g. a release or review. Waiting means context switches which
means less productivity.
Code churn
How much code are we reworking in a short period of time? High code churn
indicates delays and quality issues.
Review depth
The amount of feedback per PR.
Mean time to restore
How long it takes to fix an incident in production.
Investment profile
New functions for our customers vs bug fixing, backend or non-functional work.
DevOps is no Walk in the Park — Sabine Wojcieszak
In a park you are safe, you do not need a map, can wander where you want and you
need no preparation. DevOps is not like that.
The term CALMS has been coined by John Willis to explain DevOps. It stands for:
Culture
Automation
Lean
Measurement
Sharing
Most people talk a lot about the automation and some about the measurements
part, but very few about sharing and even less about culture.
There is a similarity with Agile where the term began as a niche but became
hyped and then mainstream, where people talk about Agile without knowing what it
is. We should prevent this from happening with DevOps.
It’s no longer business and IT, but IT is part of business. One could even
say IT is business.
DevOps is not cherry picking what we like (automation) or only picking the
low hanging fruit and calling it “DevOps.” It needs an holistic approach. But
this needs a lot of ingredients. In the right mix.
You should always ask yourself why you are doing DevOps. Do you think it is
cheaper because of the level of automation? Because everyone is doing it? To
deliver better software?
You need to understand the whole approach.
DevOps means to Sabine: deliver valuable products with better quality sooner to
customers/users. This means we need to know what is valuable for our customers,
what our customers think of as quality, etc.
The term CI/CD in context of DevOps traditionally stands for continuous integration
/ continuous delivery. But it could also stand for continuous improvement /
continuous development, if we think of products and people. But we can also talk
about continuous improvement and continuous discovery of opportunities and
outcomes.
You cannot buy DevOps—neither with tools, nor with certifications. But it’s
not for free either. You will fail for example.
Some anecdotes of where it went wrong:
“We are now the DevOps department.” Which means there is still a silo with a
lack of communication.
“We have a DevOps team that is setting up the pipelines.” Again no
communication, no transparency.
“We have a linter but it gave to many warnings so we turned it off.” No
understanding about why it is done, no trust that it helps to grow, sign of
fear to make mistakes.
“We are measured by the number of developed features, but not allowed to talk
to sales.” It’s a feature factory, measuring the wrong things. Again also not
enough communication and silos.
“IT has not reported any problems.” Be open to the obvious: if customers
complain, there is a problem. Ask yourself what is actually monitored? Not
business relevant metrics obviously otherwise the problem would have been
detected by the company instead of the customers.
DevOps is more than automation, it is CALMS.
If you don’t get the C then don’t bother with the A, L, M or S.