Virtualenv
The first tool I’ll discuss here is
Virtualenv. According to its
documentation Virtualenv is a tool to create isolated Python
environments.
What does it do?
It offers a way to install Python packages independent of the global
site-packages directory. This provides you with a way to install
packages even when you do not have permission to write in the global
site-packages directory and it will prevent conflicts with
packages installed there (or in other Virtualenv environments for that
matter).
For instance my current Ubuntu 14.04 installation has the requests package globally installed. However, it is version 2.2.1. What if I need a newer version? Or worse: what if my code is incompatible with a newer version and the package is updated for some reason (perhaps with a system upgrade)?
How do we use it?
For the project I’m working on, we have a couple of small tools
written in Python that we need running in their own separate
environment (on different machines than the code of the main
application). For these tools, creating a virtualenv seems the best
solution. To make it easier to setup the virtualenv, we have a
Makefile sitting next to the setup.py file:
lib/python2.7/site-packages/foo.bar.egg-link: bin/python
bin/python setup.py develop
bin/python:
virtualenv --clear .
bin/pip install -r requirements.txt
clean:
rm -rf bin include lib local dist
This way we can be certain that we have an isolated environment with the packages we need for this tool (and with the right versions).
Buildout
Another tool we use is Buildout. This
is a Python-based build system for creating, assembling and deploying
applications from multiple parts, some of which may be non-Python-based.
What does it do?
In contrast to Virtualenv, Buildout does not just create an isolated
environment for your project, but it is also a complete build
tool. Since there are many
Buildout recipes
available for all kinds of jobs—for instance to
generate text files from a template,
install Django,
execute commands
or to
install user cronjobs—it
is as versatile as for instance a Makefile or a shell script. This
also makes the learning curve for Buildout a bit more steep than
for Virtualenv.
How do we use it?
For the application I’m currently working on, we use Buildout to build the components of the system. One of these components is a Django application, so we’ve got this part in our Buildout configuration:
[django]
recipe = djangorecipe
settings = production
eggs =
Django
${buildout:eggs}
${buildout:dev-eggs}
extra-paths =
project = my_project
wsgi = true
wsgi-script = ../my_project/wsgi.py
But we also generate the Nginx and Circus configuration using Buildout:
[circus_ini]
recipe = collective.recipe.template
input = templates/circus.ini.in
output = ${buildout:parts-directory}/conf/circus.ini
[nginx_conf]
recipe = collective.recipe.template
input = templates/nginx.conf.in
output = ${buildout:parts-directory}/conf/nginx.conf
This is convenient for us since, amongst other things, we need to configure a port in both configurations. So the Circus template contains this section:
[socket:django]
host = 127.0.0.1
port = ${custom:webapp_port}
And the Nginx configuration template contains this section:
upstream django {
server 127.0.0.1:${custom:webapp_port};
}
This port number is set in our Buildout configuration file:
[custom]
webapp_port = 8080
Whenever we build the project, the Nginx and Circus configurations are generated using that single variable. This makes it nice and DRY.
Docker
Docker works on a whole different level to
isolate your environment. Docker is an open platform for developers
and sysadmins to build, ship, and run distributed applications.
What does it do?
Docker allows you to launch containers to run your applications in. These containers are based on so called images and these images can either be existing images built by third parties (made available via e.g. Docker Hub) or custom made images.
Using Docker is different from using a virtual machine because it does
not include a complete guest operating system. Instead it just runs
the application in an isolated process and shares the kernel with the
other containers. Or as they put it themselves: it enjoys the
resource isolation and allocation benefits of VMs but is much more
portable and efficient.
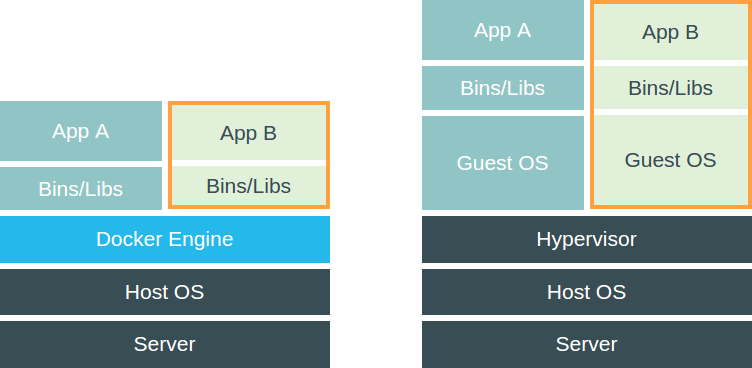
How Docker, on the left, is different from virtual machines, on the right (images taken from the Docker website)
How do we use it?
The application that is being built with Buildout, needs to be
deployed for multiple customers. To handle this deployment, we use
Docker. We create a custom image and make sure that Buildout does
its thing by having a line similar to this in our Dockerfile:
RUN cd /var/application && python bootstrap.py && bin/buildout
Earlier in the Dockerfile we make sure that the application code is
extracted to the /var/application directory. The Dockerfile also
includes commands to install packages we need on the operating system
level, for instance Nginx.
This way we have an image that contains a version of our application (and its dependencies) that is good to go. Now all we need to do is run a container based on this image. By adding environment variables, we have slightly different settings per customer.
Conclusion
The tools discussed above (Virtualenv, Buildout and Docker) can all be used to create an isolated environment for your project. In that regard they are similar.
At the same time, they all have different features so which tool is the ‘best’ solution absolutely depends on your situation. And as you can see in this article: you don’t have to chose just one.
The way I would personally ‘categorise’ them:
- If a project just needs a couple of Python packages, Virtualenv is probably a good fit.
- If the project is more complex, Buildout provides the tools to set up the environment.
- If the project needs to have a reproducible environment that also requires packages/configuration on the operating system level, Docker might be the way to go.