Last week I was working on a set of features for one of our clients. In an attempt to be a proper agile developer, I was refactoring while coding. Halfway through developing a feature I realised that my approach may not be the best solution. Still, throwing away the work that already had been done wasn’t an option because the alternative could also have turned out to be a bad idea. To make matters more complicated: the history made it hard to create a branch somewhere in the past: I would either have to throw away useful code, or mess up the history with code I wouldn’t ever use.
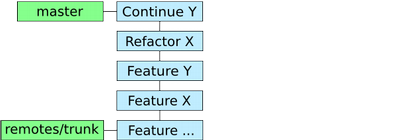
Repository at the start of this story
Luckily I was using Git and I hadn’t pushed the relevant code to the Subversion repository yet. (A simplified graph of the history is shown in the image. The blue boxes represent the commits and the green the references.)
The first action was to get the history sorted out. Since I made small
commits and thus not mixed features in the commits, I could easily
reorder them. Running “git rebase --interactive <sha1>” with the
SHA1 of the right commit popped up the editor where I changed the
order of the commits and I was done.
The next step was creating a branch from the current HEAD. Since, as far as I understand, a branch is just a reference pointing to a certain commit, this action made sure my first attempt to implement feature Y was saved. Still, I wanted to work on the code without my first attempt being there. By resetting the current HEAD to an earlier commit without the feature Y changes, this was possible.
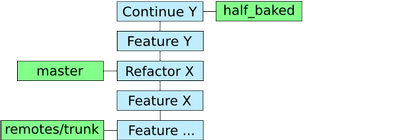
The repository after rebasing, branching and resetting
Now, not falling into the same trap twice, I created a new branch from master to try out the new way of implementing the new feature. Happily committing away on this new branch I was able to make up my mind about which approach would be the best and quickest solution. In the end I decided to go with the new approach and merged it with master.
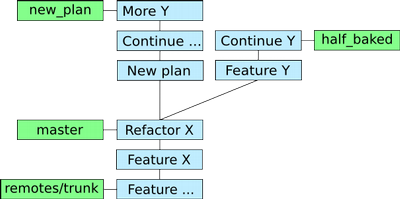
The repository right before merging
Now for the anticlimax of the story… The whole exercise was about
trying out a new way of implementing a feature without messing up the
Subversion repository. Although Git helped me all the way, the human
again proved to be the weakest link. By mistake I pushed the branch of
the half baked implementation to the repository. A quick “svn merge”
restored the situation and I pushed the master branch to the
Subversion repository after all. (I probably could also have used Git
to undo the commits, unfortunately I was in a hurry and didn’t know
how from the top of my head.)
Lessons learned:
- Git is really flexible and, as Ryan Tomayko states, it means never having to say “you should have”.
- You still have to do the thinking yourself. :)