PyGrunn is a Python focussed, one day conference held in Groningen1. Or as the organizers more eloquently phrase this:

PyGrunn is the “Python and friends” developer conference with a local footprint and global mindset. Firmly rooted in the open source culture, it aims to provide the leaders in advanced internet technologies a platform to inform, inspire and impress their peers.
Before I start with my notes I want to give a shout-out to Reinout van Rees. His (PyGrunn) summaries are excellent. I’m always impressed by the quality of them and how little time he needs to write them. Where I’m only able to make notes and need to write them out afterwards, Reinout has the summary (as a coherent story) ready before the speaker has unhooked their laptop. So if you are interested in one of the talks he has attended, head over there first.
Platform Engineering: Python Perspective — Andrii Mishkovskyi
Why do platform engineering teams exist? We’ve seen a “shift left” of responsibilities towards the developer e.g. QA, operations (DevOps). But we (software developers) are trained to write code, not to e.g. monitor it.
So where does a humble developer start? There is an abundance of choices on the tools to use. What do you pick for package management? Or continuous integration? Or deployment, code quality, observability, etc. This freedom of choice comes with a cost. We start with discussing which tools to use instead of the problem the customer is facing. And depending on which choice we make, the result may make reasoning about the software more complex.
So what should you do?
Andrii broke it down into three parts:
- You observe (i.e. you read a lot to get the lay of the land)
- You execute (this is the actual software development part)
- And then you collect feedback (you reach out to teams, you observe how their work has changed)
Some of the platform engineering team deliverables:
- Documentation
- Self service portal (tip: look into Backstage)
- Boilerplates
- APIs
The “consumers” are developers, compliance teams and other platform teams. The goal is to:
- Have reasonable defaults
- Remove redundancy
- Keep things consistent
To get a feel for the scale of things: at Andrii’s company there are over 160 services, developed on by 300+ developers in 500+ repositories. They total up to 3 million lines of code and 6 million lines of YAML.
Templates (boilerplates) provide a paved path. The goal is to have teams spend as little time as possible when starting a project. The templates use a certain set tools that are supported. Teams are free to use different tools though if they want to.
Andrii uses cookiecutter templates at work. It’s not his choice perse, but it’s what was already in place when he joined. There are currently three templates in use. They have evolved over time. For example in the last nine years, over 800 changes have been made (that is more than one change per week on average).
The evolution has left its marks: the templates have a lot of code duplication. There is also code specific to a tiny minority of projects (only about 8 out of the 500+). This means that most projects start with deleting code after using the boilerplate.
And that also relates the downside of using cookiecutter the way they do. Instead of just using it to get started with a project, they also use it incrementally. But cookiecutter does not have versioning built-in. So if you remove a file and then reapply cookiecutter again, the file is happily created again.
While Andrii is aware of the issues (and thinks copier might be a better alternative), it is hard to replace practices that are already in use. And cookiecutter is great for getting started with a project.
With regard to the standardization, they use the following in the templates:
pyproject.tomlfor all projects- Poetry (instead of setuptools + pip-tools)
- sprinkle Renovate on top for automatically updating dependencies
As it currently stands, there are 99 project that migrated to pyproject.toml and
Poetry in the last 2 years. It makes sense because it takes time for projects to
transition. Plus they are not required to migrate; again: the template are there
to help, not to limit the users. Renovate has been adopted more quickly.
Migrating from e.g. pkg_resources to pkgutil or
PEP-420 for namespaces packages is hard.
Templates can help with that. However, cookiecutter does not actually manage
files. So if a file has been removed from a template, rerunning cookiecutter
does not remove the file from the project. So that requires some care.
When they migrated from a monolithic application to a microservices architecture, authentication/authorization became an issue. There was no visibility for teams, no transparency and no accountability. To combat this, they created an API where applications can declare the required access and scopes in a YAML file. Maintainers can approve this access. And this also allows for CI/CD to check access. A CLI tool can verify the validity of the YAML and check if access is actually approved.
Securing your team, solution and company to embrace chaos — Edzo Botjes
Edzo started by sharing a link to his slides and warned us that it usually takes two weeks for people to digest the contents of his talk. He would overload us with information. And that’s where I decided to solely concentrate on the talk and not on note taking.
Nobody knows what they are doing. Embrace this.
Even a simple, deterministic system like a double pendulum has a nondeterministic outcome. In other (my) words: the whole world is in chaos and unpredictable.
When presented with information everyone processes it differently and understands something else (also see viral phenomenon of the dress).
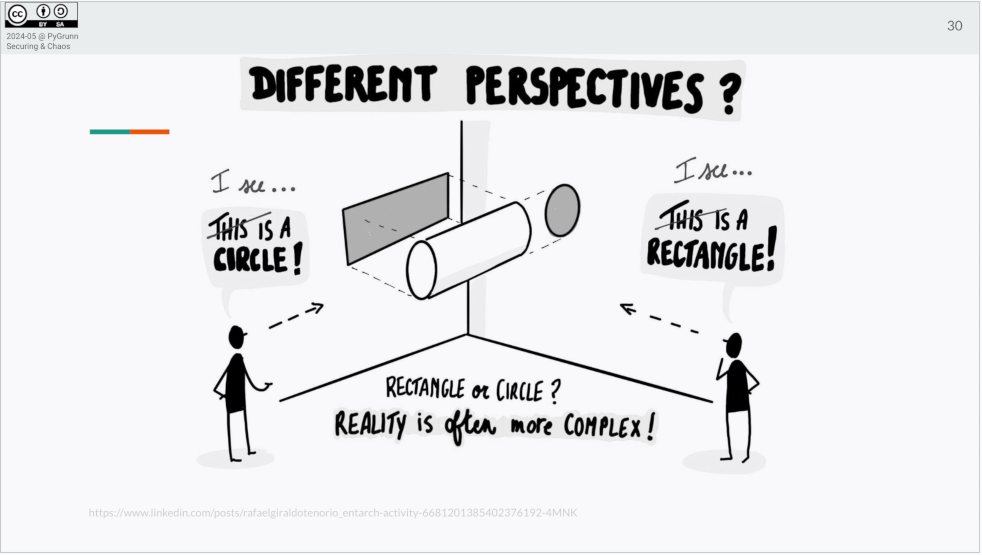
What worked for Edzo was to embrace chaos. To do this he let go of his desire to control and trying to create a predictable outcome.
Descriptors: Decoding the Magic — Alex Dijkstra
Many people have used descriptors without them even being aware of it.
From the documentation:
Descriptors let objects customize attribute lookup, storage, and deletion.
You can view descriptors as reusable @properties. A descriptor implements the __get__ and
__set__ methods (and when needed __delete__).
Alex showed a bunch of examples. This is the template he showed to introduce descriptors:
class MyDescriptor:
def __get__(self, obj, owner):
# owner is the class to which the instance belongs
return obj.__dict__.get(self.private_name)
def __set__(self, obj, val):
# self is descriptor instance.
obj.__dict__[self.private_name] = val
def __set_name__(self, owner, name):
self.public_name = name
self.private_name = f'_{name}'
His example of how to use this:
class MyClass:
value = MyDescriptor()
myinstance = MyClass()
myinstance.value = 5 # MyDescriptor.__set__
myinstance.value # MyDescriptor.__get__
Using descriptors you can do things when getting or setting the value. E.g. in a class you can enforce that an attribute has a certain type.
The __set_name__ method was introduced in Python 3.6. It is not needed to use this in all of your
descriptors, but also doesn’t hurt.
Do you want to use descriptors all over the place? No. They can be useful: you can create a clean APIs with them and this helps if the API is used frequently. However, it does create some overhead and the code is a bit more complex.
Resources:
- https://docs.python.org/3/howto/descriptor.html
- Luciano Ramalho’s book Fluent Python (Luciano also did a few talks about descriptors)
Release the KrakenD — Erik-Jan Blanksma
KrakenD is an API gateway product. Erik-Jan likes it so much he wanted to share his experience with it.
Projects can start out simple, with a monolith that is accessed via a web client. Before you know it, there are several services and multiple types of clients. The solution is to introduce an API Gateway in the middle. It can then handle the incoming requests.
API Gateway in short:
- It sits between clients and backend (as a sort of portal).
- It hides internal complexity of backend for the clients.
- The gateway is a great place to introduce things like authorization/authentication, logging, load balancing, caching, etc.
KrakenD is one of the available API Gateways. It is open source, but there’s also an enterprise version with extra features. KrakenD is implemented in Go and offers a bunch of features out of the box (monitoring, throttling, request and response manipulation). KrakenD offers integrations with e.g. tools (Jaeger, Grafana, the Elastic stack), authorization/authentication services and queues (RabbitMQ).
KrakenD is a stateless process, so no database is needed. It takes JSON (or YAML) config. It can combine the results of multiple backends API calls and return it as a single response.
Tips:
- Use the KrakenDesigner (makes it easy to explore what’s possible). Note that you do not want to use this in production.
- You’ll want to split up the configuration when it grows. By using flexible configuration you can combine so called partials, settings and templates.
- KrakenD can check and even audit you configuration.
- Since the configuration is in JSON, you can generate OpenAPI.json from the KrakenD config. You can use this for Swagger.
KrakenD is a great tool to manage your APIs. It is lightweight, fast, easy to configure and has lots of functions out of the box. It is versatile and extensible. By using it you can make your architecture more agile.
However, it also means that you will have to manage the API Gateway configuration. And a change in the configuration means you will have to restart the process.
General tips
Some general notes:
- Have a look at:
- It can be helpful use functional programming (e.g. using closures) instead of by default using classes and methods.
-
“Grunn” is what Groningen is called in the regional language ↩︎

