DevOpsDays Amsterdam 2016: Day Two
Table of Contents
My notes from the second day of DevOpsDays Amsterdam 2016.
What we’re learning about burnout and how a DevOps culture can help — Ken Mugrage (ThoughtWorks)
Ken considers his talk a success if we think the subject is important enough to talk about this with everyone you know (co-workers, family, etc).
Before talking about what DevOps can do to help, let’s first define what DevOps is. According to Ken, it is “a culture where people, regardless of title or background, work together to imagine, develop, deploy and operate a system.”
Burnout is nicely defined by Merriam-Webster as:
the condition of someone who has become very physically and emotionally tired after doing a difficult job for a long time.
Dimensions of burnout:
- Exhaustion
- Cynicism
- Professional Efficacy
Burnout is more likely when there is a mismatch between what you have to do and what you want to do or feel comfortable doing.
DevOps can help with several common areas of mismatch:
- Work overload
- Work is more visible.
- More load sharing.
- Less deployment marathons (due to continuous delivery).
- Lack of control
- Teams are responsible for decisions.
- Use the right technology and tools for the team.
- Breakdown of communication
- Everyone involved with product is in the same team.
- Pairs with different skill sets are common.
- Swarming can be done when needed.
- Blameless retrospectives are held.
- Absence of fairness
- You build it, you run it.
- Everyone responsible for quality.
- Everyone is measured the same way.
So no more of this:

Note that a “DevOps team” does not exist: creating another silo is not a solution for silos.
Some things you can do:
- Pay attention to how you feel. (And address it somehow.) Use the Maslach Burnout Inventory.
- Talk to someone. It is (or easily can turn into) a medical issue.
- Listen to someone. (But: although empathy is great, you are not a professional so don’t act as one.)
- Get training. There is such a thing as a mental health first aid training.
You can use the slides from this talk, except for the ThoughtWorks logo.
Book recommendation: The Phoenix Project: A Novel about IT, DevOps, and Helping Your Business Win.
Preparing for the Day After Tomorrow - Test-Driven Infrastructure — Victoria Jeffrey (Chef)
This talk boils down to integration tests for your infrastructure.
Servers and cookbooks are tested separately. Why would you then want to be clicking around to check if it worked as expected? You could integrate tests in your project to do this for you.
First establish infrastructure expectations. Then make sure that test for those expectations end up in your CI pipeline. Treat your infrastructure like your software.
A language to describe infrastructure expectations is InSpec. Developers, ops and even security people can write tests that can be executed against the infrastructure.
You can use InSpec for machines that have been provisioned manually, with Ansible, Puppet or Chef. This is because InSpec only checks the final state. The InSpec runtime runs on your local machine (keep this in mind when writing tests) and it does not depend on a tool on the server.
You can use Ruby language in the tests.
Black box testing is not the intention of InSpec, although you could do that if you want to. You might want to use other tools for that however. InSpec is looking on the server to check if things are as they are supposed to be.
Continuous testing in the world of APIs — Desmond Delissen (IceMobile)
Desmond talks about the mistakes his company made with testing.
Test data
Initially they kept it simple: each developer had static test data in their database. This did not work because the data diverged and tests started breaking.
Next step: use the APIs to create test data. This sounded like a nice idea, but because they were depending on other services, this did not work in practice.
Now they use a script to load data into database when running the tests.
Processes around tests
In the past, the tester created ideas on paper and the developers automated and maintained the test. This was not a success. Developers did not know what the tests were testing and would rather build new features than create and maintain the tests.
The new process is this:
- A developer creates a merge request.
- A tester starts automating the test.
- The tests are reviewed by another tester.
- The changes are merged into develop.
- The test are ran on develop.
- They do manual testing.
If everything checks out, they can push to acceptance.
Tool stack
In the past they used a couple of different tools. They decided they needed a uniform way to create tests.
So they:
- Created Minosse (which uses Cucumber underneath).
- Replaced the email that Jenkins used to send to an email list, with posting the results of the nightly build in a Slack channel.
- Tag every feature.
- Use a code coverage tool to see if they missed a function with a test.
- Store all test results in a database to see if a test is flaky.
- Have a dashboard.

What did they do wrong?
- Test data creation
- Process of creating tests
- Agreements surrounding the tests (who maintains them, etc)
They learned from these mistakes and made changes. Desmond (a tester) can now use his time more for exploratory testing.
One engineer, four environments, no termination protection — Harm Weites (Wehkamp)
A journey story about an event that happened last March.
BLAZE
The original stack at Wehkamp is a monolithic application using the Microsoft stack, so .NET, IIS, MS SQL.
The new stack Wehkamp is using consists of Linux, HAProxy, Mesos & Marathon, Python & Scala & Node.js. But they also use: Prometheus, Elasticsearch (for web search and logs), Cassandra, Consul, Kafka, Fluentd (because Logstash wasn’t working out for them) and Docker.
They called this stack “BLAZE” instead of something boring like “Wehkamp e-commerce stack”.
They are using AWS with couple of virtual private clouds (VPC), e.g. one for dev & acceptance, one for production and one for supporting services (Jenkins, etc), and spaces (e.g. one for NL, one for BE). They built micro services (one service, simple task, e.g. “search” or “checkout”) and heavily rely on open source software.
All their code is on GitHub, some of the repositories are public.
Currently: 79% of all traffic is going through the old, .NET architecture. Only the ’lucky few’ in the remaining 21% will use the new stack. They use a load balancer to do this.
March
In March they were going to be handling 1% of the production traffic with BLAZE. The Belgian site already used BLAZE, but that traffic cannot be compared to the Dutch site. So this was a big moment for the team.
In this period a guy joined the team and started to learn Ansible—which is what they use to provision machines. The guy was told he could use the dev VPC. He made an error which terminated all (but one) instances in the development and acceptance VPC. This happened only 5 days before they would start to handle real traffic.
To recover, they ran the playbooks. And more playbooks. And even more playbooks. It involved lots of waiting while the playbooks ran and lots of bug fixing the playbooks (“when was this playbook last run?!”) But they got their environments back after 48 hours.
Who made the actual mistake is irrelevant. More important is the question “what did the team forget to make this error happen?”
Lessons learned
- AWS: isolation, isolation, isolation. E.g. dev NL from dev BE, separate accounts for e.g. LUKS, backups, etc.
- Deployments:
- Nightly builds (of the entire infrastructure).
- Termination protection (termination policy in the EC2 module of Ansible so you cannot destroy machines unless you explicitly remove the policy).
- Even more automation.
Things they want to change next:
- Get Jenkins to run playbooks.
- Fresh start each morning: rebuild the ‘playground’.
The development environment is already shut down each night and in the weekends to save cost (and no-one should be working then anyway). Rebuilding the complete development environment each day is something they are currently not doing yet.
Currently it takes about 1 hour (max 2 hours) instead of 48 hours to rebuild. And now they know it works instead of thinking that it works.
Ignites
Ignites are five minute talks with twenty auto-advancing slides in which you can share anything you want: tips, tools, war stories, etc.
An Elasticsearch Cluster Named George Armstrong Custer — Will Button (Trax)
Elasticsearch is easy to get up and running. But scaling is hard. It feels like a battle.
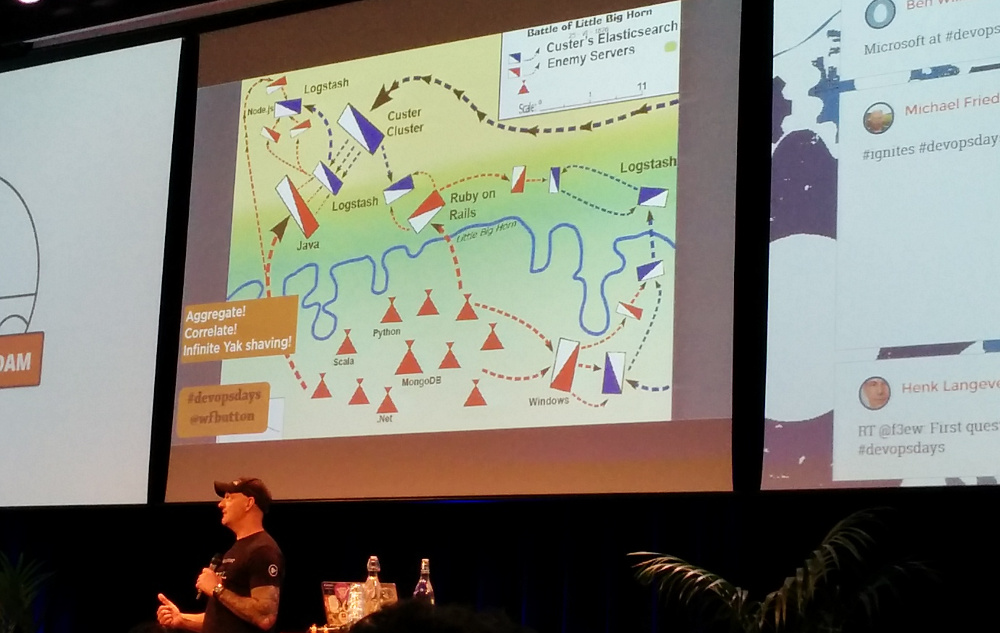
What could go wrong with putting everything in Elasticsearch?
When one of their servers would crash, it took out the whole cluster. They created a script to automate restarting the cluster, which bought them some time to find the actual problem.
They started to gather metrics using the Elasticsearch’s “_stats”
API. What they noticed was that the JVM heap utilisation displayed a
saw tooth on the new environment (due to garbage collection), but it
did not on the old environment. After they started monitoring this
behaviour, they could restart things before the cluster broke.
In the end, the problem was not Elasticsearch, but lack of resources to win the battle and not enough monitoring. It is important to have trends from day one. Also note that internal Elasticsearch monitoring is not enough: if Elasticsearch is down, your monitoring is also down. They used an external load balancer for the monitoring.
Teamwork is critical.
New technology means new ways to screw it up. This is why having a blameless environment is important!
The Zabbix templates from Trax can be found at https://github.com/mkhpalm/elastizabbix
Test driven Dockerized infrastructure — Gopal Ramachandran (TMNS)
Treat infrastructure as code and use test driven infrastructure.
Some tools you can use:
- Serverspec
- Containerspec, which is built on top of Serverspec and Cucumber. You can use this for testing Docker containers.
- Test Kitchen, while mainly for Chef, can also be used with other configuration management tools.
- Goss, written in Go. Replacement for Serverspec.
- Testinfra, a Python equivalent of Serverspec.
Systems are Simple. Humans are Complex — Hannah Foxwell (Pendrica)
Fixing a broken culture is hard. You will have to change beliefs and values, which is hard.
When people are in a stressful situation, their “reptilian brain” (the oldest, ’legacy’ brain) automatically takes over. It would be good to take a step back in those situations and think about what we are doing.
However, self regulating all day, every day is not possible. Your resources are limited. Change is hard, but important. Keep trying and you will get there.
Look after your humans. They are complicated, but incredibly important.
Working in and with (Open Source) Communities — Bernd Erk (Icinga)
Lost of ways to create a community. There are important things to keep in mind.
For a member:
- Everyone is an equal member with the same priority.
- Disagree with ideas not the people.
- Bring new members and take care of the next generation.
- Don’t be a redshirt, instead be a valuable member of your community.
For a leader:
- Maintain a balance between strong and weak members.
- Take care of internal culture.
- Don’t be a control freak.
- Create a transparent environment.
Maintenance & rules:
- Talk, talk, talk. Meet the people.
- Be nice as long as possible.
- Don’t accept harassment.
- Having a Code of Conduct is important (but it is not enough: not everyone reads it).
- Taking care is even more important.
Open Source Operations - punching above your weight — Marco Ceppi
Every problem has at least three software solutions. All of them are right, but all are different. Now you have two problems: the original problem plus you have to choose which software to use. (Or three problems if you choose to write your own solution.)
You need to be an expert to be able to evaluate the solutions / software. What to chose? How to put it into production? How to run it?
Software is no longer scarce, but now operations is.
Do the same thing for operations as we did for software: share knowledge and experience.
Ops doesn’t make you special, you application does. Ops is not your secret sauce.
Pentesting ChatOps — Melanie Rieback (Radically Open Security)
Last year at DevOpsDays there was a workshop about ChatOps from GitHub. Melanie figured it could also be used for penetration testing (pentesting for short). Her company experimented with it since last year.
ChatOps is a concept created by GitHub. It’s basically DevOps from their central chat application. They can use their chatbot for e.g. deployments, monitoring and other interactions with DevOps tools.
GitHub created their own chatbot: Hubot. You can issue commands and write scripts for it. You have to write CoffeeScript for the interface, the backend can be whatever you want.
Radically Open Security is using RocketChat. It is basically an open source version of Slack and you can host it yourself. The latter is very convenient for Melanie’s company since they are not comfortable with putting the pentest results in Slack. RocketChat has a large number of integrations with, for instance, ticketing and CI systems.
Radically Open Security has its own bot and uses it for a number of things, such as reporting. They open sourced their set of tools to create these reports. It’s even going to be an OWASP project (PenText?).
Customers are also invited in pentest channels. The company has a “peak over our shoulders” policy. Customers can observe or participate in the pentest.
Example: they divided a customer team in a red and a blue team. Under guidance of two pentesters they tried to hack their own software. At the end of the week 40 vulnerabilities and complete attack path were reported. The biggest success was when a developer said “I will never look at development the same again.” For the price of a normal pentest that customer got a whole experience. Without ChatOps this would not have been possible.
At Radically Open Security the RocketChat bot interacts with their GitLab instance. It is used for reporting: GitLab issues are in Markdown which is then converted to XML to become a report. A big advantage of ChatOps in this case is that no-one has to install the tool chain locally. The bot will generate the report for you.
Another form of integration: they have their KanBoard tied to ChatOps.
More integrations:
- Scanning + Exploitation (nmap, w3af, sqlmap, hydra, etc)
- Reconnaissance (whois, Google, their own PassiveScanningtool, etc)
- Cryptography (hash cracking, rainbow tables, etc)
- Other (Email/SMS integration, spearphishing, CVEsearch)
For the phishing: you can get a real-time announcement in RocketChat when someone clicks on the phishing link.
You only have to give someone access to the chat to make the tools available. Super easy when onboarding people.
Radically Open Security open sourced a bunch of stuff. Check out their repository at https://github.com/radicallyopensecurity.
There are already a lot of pentesting tools available, they only have to write the CoffeeScript for the interface. Integration done via web services.