Open Source Summit Europe 2018: day three
Table of Contents
My notes taken on the third and final day of the 2018 edition of the Open Source Summit Europe.
These are just notes. They are not proper summaries of the talks.

The dates for the Open Source Summit next year:
- August 21–23 in San Diego, California
- October 28–30 in Lyon, France
DevOps Meets Docs: Documentation as Code — Robert Kratky (Red Hat)
Documentation as code means writing, testing, publishing and maintaining
documentation using the same tools developers use for software code.
Advantages of using plain text for documentation, instead of e.g. Word, are that plain text is more accessible and it is easier to do validation. You can also use the same version control tools you use for your code.
You could use issue trackers to automatically generate e.g. release notes.

You can build and test each commit/pull request (continuous integration). You can test all kinds of things: are components indeed available, are links valid, etc.
Generating documentation is one, publishing it is another thing. You could automatically deploy your documentation (continuous deployment).
To make the barrier to entry for contributing lower, you could use a containerized toolchain. This way people can contribute without having to worry about installing all required tools on their own system.
Multiple parties benefit from documentation as code:
- Developers
- Familiarity with the toolchain
- Encourages quick contributions to the docs
- Writers
- Tight integration with the development team
- Continuous collaboration
- Better integration with other teams, like QA
- Integrating writers with developers increases sense of responsibility; documentation is no longer a second class citizen
- Organization/project
- No vendor lock-in (format, tools)
- Tighter integration of teams, departments
There are challenges though. Both writers and developers may resist. Writers have to retrain and it may be a steep learning curve. Developers may feel that doing documentation properly might slow down the development process. Since the documentation is more visible now, developers might become conscious of their language and grammar skills.
There are also technical challenges. Converting to another format might not be trivial and even lead to a disruption in the release cycle. There may also be resource and staffing issues.
(Slides)
What are My Microservices Doing? — Juraci Paixão Kröhling (Red Hat)
A microservice is observable if we can analyze its metrics, logs and tracing information. But you need more than metrics or logs of individual containers. You want the aggregation of all of them to see what is going on and detect patterns.

Distributed tracing tells a story of a request though our services (which services were touched, when, etc). It is especially useful when doing root cause analysis or you want to optimize performance (where am I spending most of my time).
But how does it work? A “span” is a data structure to store units of work in (what, when did it start, etc) plus metadata. Tracing includes references to other spans so you can build graphs of those spans.
Instrumentation can be both implicit and explicit. Explicit instrumentation is done in your code itself. Implicit instrumentation is done via the frameworks you use (e.g. in Sprint Boot in a Java project).
The OpenTracing project wants to document terminology so we are all talking about the same things. After documenting, the next step is offering an API (which the project does for 9 languages at the moment). The result can be used in compatible projects like Zipkin and Jaeger.
Jaeger is a client side tracer that collects data. It sends it to a backend component for storage. A frontend component can then display the results. Jaeger runs on bare metal, OpenShift and Kubernetes.
Data storage for Jaeger is typically on Elasticsearch or Cassandra.
Have a look at OpenTracing API contributions GitHub organization.
(Slides)
An Introduction to Building Clouds with Apache CloudStack — Dag Sonstebo (ShapeBlue)
Apache CloudStack is a scalable,
multi-tenant, open-source, purpose-built, cloud orchestration platform for
delivering turnkey Infrastructure-as-a-Service clouds.
Virtualization is never going to go away.
Features:
- Broad hypervisor support
- Scalable architecture
- High availability (for VMs and hosts)
- Multiple interfaces (web, CLI, API)
Active community: ~200 project committers, last month 25 merged PRs from 16 authors, plenty of mailing list activity. Once a year there is a CloudStack Collaboration Conference.

You can use CloudStack for private cloud, public cloud or a combination of both in a hybrid cloud.
What can CloudStack give you?
- User friendly self service of all resources
- Automation of all provisioning through API
- Compute
- Storage
- Networking
- Templates
CloudStack can be seen as competition to OpenStack. However, CloudStack is vendor neutral. As a result it is a bit of the invisible man in the cloud infrastructure space.
Why CloudStack?
- Integrated end-to-end IaaS product
- Proven at scale
- Rapid time to value
- Low implementations & operational costs
- True multi-tennant
- Focused, user led, development community
- Narrow scope / easy integration
Hashicorp Terraform: Deep Dive with no Fear — Victor Turbinskii (Texuna)
Terraform is a resource orchestration management tool, not a configuration management tool. So you cannot compare Terraform with e.g. Ansible, Puppet or Chef.
It is not a cloud agnostic tool. It does however provide a single configuration language.
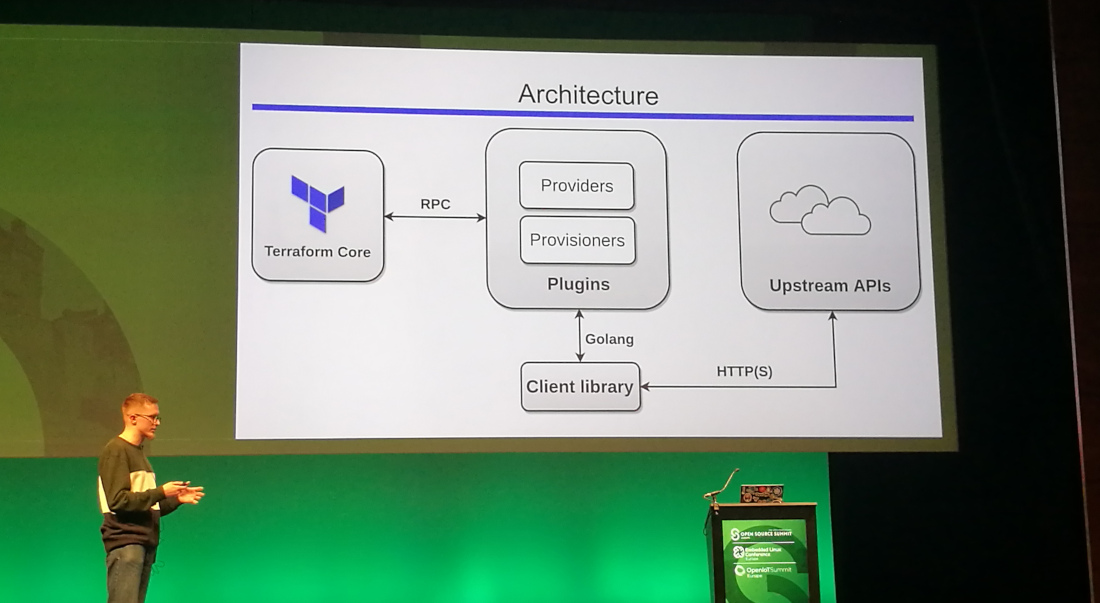
About a year ago, the Terraform Module Registry was introduced.
Chef and SaltStack are supported by Terraform; Ansible not (yet).
Tips:
- Use “
terraform plan -destroy” to safely review the destructive actions. - Use backends like S3 to backup your state files (use versioning and use encryption via KMS)
- You can either use “data” resources to access resources created by other teams, or use their remote state.
- Use the “
TF_LOG” and “TF_LOG_PATH” variables for logging. - Use Delve (a Go debugger) to learn how Terraform core works. (Well integrated wth VSCode.)
- For anything else than simple scenarios, isolate state files and use workspaces.
- Use constraints to ensure that newer versions will not automatically be downloaded.
- Use “
terraform state rm type.resource.name” to keep resources but remove them from your state.
(Slides)