Devopsdays Amsterdam 2019: workshops
Table of Contents
For the fourth year in a row, I was able to go to devopsdays Amsterdam. And as usual I also joined the workshop day since I really like the deep dives these workshops provide.
I selected two Terraform workshops and one about AWS Lambda this year.
Terraform Workshop — Mikhail Advani (Mendix)
Mikhail provided a Git repository to use during the workshop: https://github.com/mikhailadvani/terraform-workshop
To dive right in, have a look at this snippet to write a file to the current
directory (in this case the in the part-1 directory of the workshop repo):
resource "local_file" "user" {
content = "..."
filename = "${path.module}/${var.filename}"
}
Terraform does not accept relative paths. But using absolute paths means you’ll probably end up with a path containing a home directory of a specific user, which is annoying for team members that have a different username.
To prevent this, you can use the “${path.module}” variable just like in the
example above. You can also use Docker to have a standard environment you run
Terraform in. Using Docker can also be a practical approach when you want to use
Terraform in your CI.
You also cannot have one variable refer another (at least, in Terraform 0.11). You’ll have to use a local value, for example:
locals {
filename = "${var.name}.txt"
}
Mikhail demonstrated the use of:
-
terraform plan -var-file=<filename>: this allows you to provide values for your variables (docs). -
terraform plan -out=<filename>: you can save your plan. If you feed the “terraform apply” command this file, it will not ask for confirmation since Terraform assumes the plan has already been reviewed (docs).If your (remote) state has changed between generating the plan and running
applywith that plan, Terraform will detect that and fail. -
depends_on: ensure that resource A is created before B.
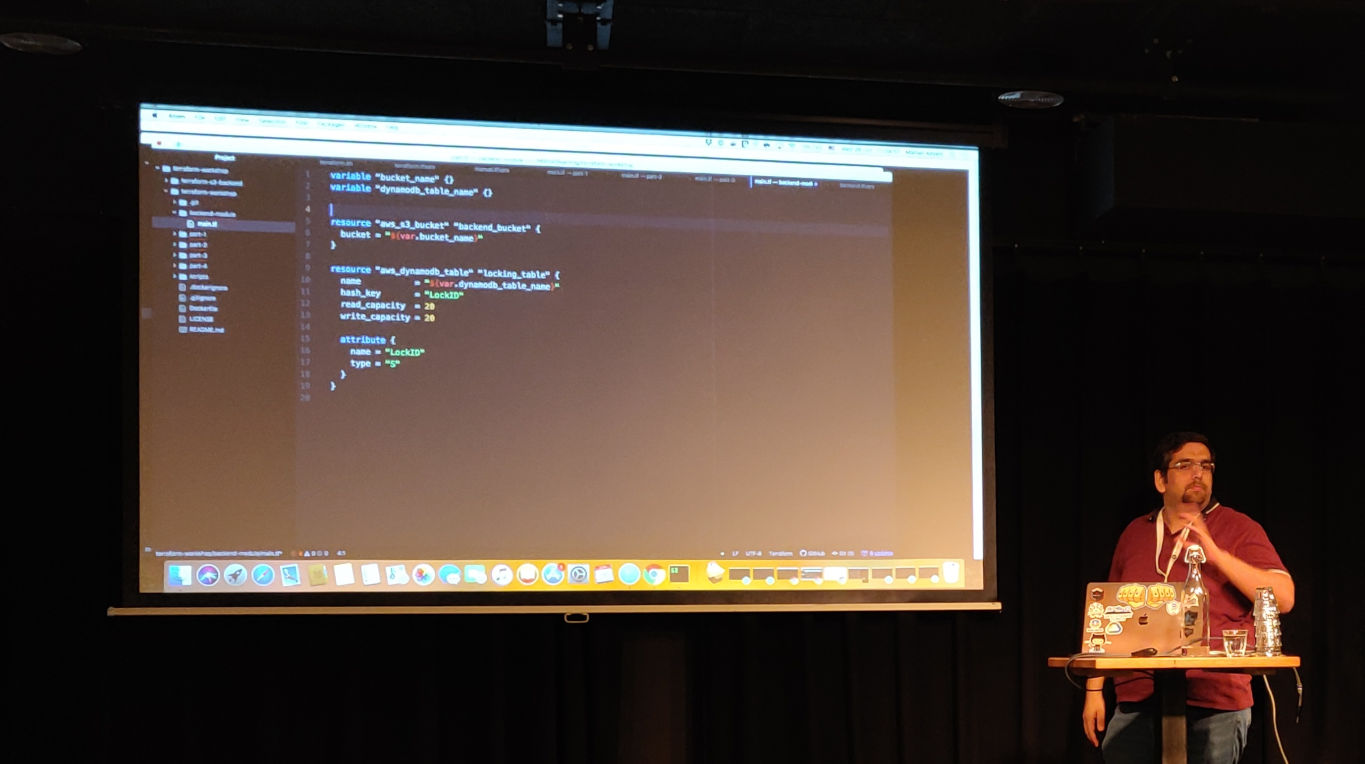
If you work in a team, you want use something like S3 for the state file and DynamoDB for locks. And you probably want to use Terraform to create the S3 bucket and the DynamoDB table. But to be able to create infrastructure you need to have a state file. Catch-22. To solve this, you’ll have to split this up in two phases:
- In the module where you define the S3 bucket and DynamoDB table, you don’t
add the S3 backend initially and run
init,planandapply. This will create the resources, but keep the Terraform state locally. - Once you are done, you can add the S3 backend and run
terraform initagain. Terraform now picks up that the state should be stored remotely and offers to move the current state.
Note that Terraform will create resources in parallel.
How do you manage secrets? Mikhail is using a secret.tfvars file and
git-crypt. The benefit of using
vars files over environment variables is you can put the former in version
control. The official recommendation is to use
Vault (also made by Hashicorp). You can
possibly also use e.g. an AWS service to store your secrets.
If you rename resources or move them into modules, Terraform detects that a
resource is no longer in your code and also picks up the new resource. It will
try to delete the old one and create the new resource. To prevent this, you’ll
have to tell Terraform the resource has moved. Use “terraform state mv”
(docs) to fix this.
An example of a module using Terratest to test the Terraform code: https://github.com/mikhailadvani/terraform-s3-backend
Tips from audience:
- Use “
terraform validate”. - You probably don’t want to put your Terraform state in version control since it can contain credentials in plain text.
Terraform best practices with examples and arguments — Anton Babenko
There are different types of modules:
- Resource modules
- Infrastructure modules
A composition is a collection of infrastructure modules. An infrastructure module consists of resource modules, which implement resources.
You can use infrastructure modules e.g. to enforce tags and company standards. You can also use things like preprocessors, jsonnet and cookiecutter in them.
Terraform modules frequently cannot be re-used because they are written for a very specific situation and sometimes have hard coded assumptions in them.
Don’t put provider information in your module. For instance: although you can specify module versions, please do not do this:
# Don't do this!
terraform {
required_providers {
aws = ">= 2.7.0"
}
}
Avoid provisioners in modules. Use public cloud capabilities instead, like user_data. (Mark: for an example, see https://github.com/sjparkinson/terraform-ansible-example/tree/master/terraform)

Traits of good modules:
- Documentation and examples: use terraform-docs
- Feature rich
- Sane defaults
- Clean code
- Tests
More info: Using Terraform continuously — Common traits in modules
Organizing your code
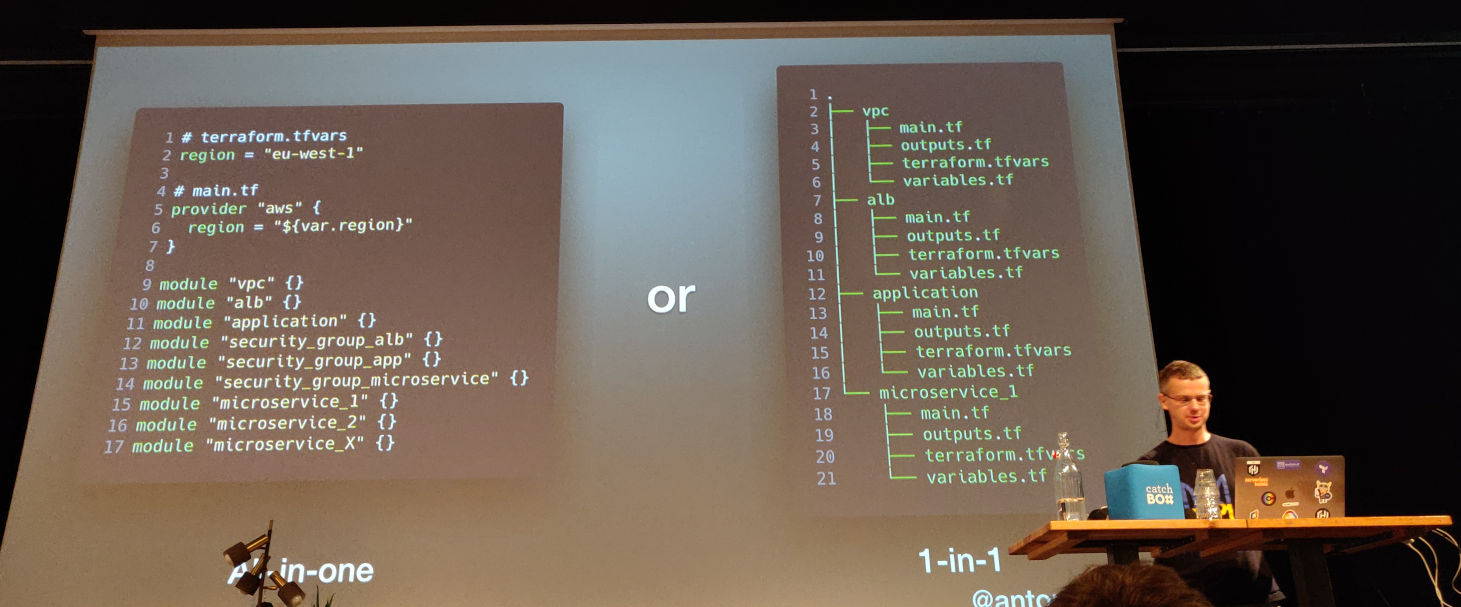
There are two opposite ways of structuring your code
- “All-in-one”, which has the benefit that variables and output are declared in one place, but one of the downsides is that the blast radius in case of a problem can be quite large.
- “1-in-1” has benefits like a smaller blast radius and that it’s easier to understand. Downside is that things are more scattered around.
TerraGrunt reduces amount of code
to do similar things.
It has extra features like execution of hooks and a number
of additional functions. TerraGrunt is opinionated.
Terraform workspaces are the worst feature of Terraform ever. (Provisioner is the 2nd worst.) Workspaces allow us to execute the same set of Terraform configs but with slightly different properties. (For example: if this is the production environment spin up 5 instances, else 1 instance.) Workspaces are not infrastructure as code friendly. You cannot answer, from the code:
- How many workspaces do I have?
- What has been deployed in workspace X?
- What is the difference between workspace X and Y?
Better: use reusable modules instead of workspaces.
Terraform 0.12
Will it help us?
It’s the biggest rewrite of Terraform since its creation. There are backward incompatible changes though.
Main changes:
- HCL2 simplified syntax
- Loops
- Dynamic blocks (
for_each) - Conditional operators (
... ? ... : ...) that work as you expect - Extended types of variables
- Templates in values
- Links between resources are supported (
depends_oneverywhere)
(The Hashicorp blog has a number of articles about Terraform 0.12 if you want to know more.)
Terraform developers write and support Terraform modules, enforce company standards, etc. Terraform users (everyone) use modules by specifying the right values; they are the domain experts but don’t care too much about the inner workings of the Terraform modules.
Terraform 0.12 allows developers to implement more flexible/dynamic/reusable modules. For Terraform users the only benefit is HCL2’s lightweight syntax.
There is a command to check your code for 0.12 compatibility: “terraform 0.12checklist”. Once everything is fine you can use “terraform 0.12upgrade”.
See the upgrade guide for
more information.
Note that the 0.12 state file is not compatible with the 0.11 state file. If you have a remote (shared) state, once one member of the team upgrades to 0.12, the whole team needs to upgrade.
Best practices
- Check the official documentation
- Hashicorp tutorials/workshops
- Anton’s Terraform Best Practices (It’s not very up-to-date though, according to Anton himself.)
Workshop/Q&A part
Anton has a workshop you can do on your own pace at https://github.com/antonbabenko/terraform-best-practices-workshop. The workshop builds real infrastructure using https://github.com/terraform-aws-modules.
During this section of his session Anton answered a bunch of questions people in the audience had. Tools that were discussed:
- Terraform pull request automation with Atlantis
- Prettify plan output using scenery (not needed in Terraform 0.12)
- Use Terraform while writing in a programming language instead of HCL with Pulumi
- Build your infrastructure as code: modules.tf
- Visualize your cloud architecture: Cloudcraft
Other resources
Getting started with Serverless development with AWS Lambda — Yan Cui
Related repository: https://github.com/theburningmonk/getting-started-with-serverless-development-with-lambda-devopsdays-ams
There is a (soft) limit of 1000 concurrent running Lambdas. This can be increased by sending a request to AWS. But even if you convinced Amazon to increase it to for instance 10.000, they only scale up at a rate of 500 per minute. So if you have a workload where you have sudden spikes and need to scale quickly, Lambda might not be what you need.
Note that you can set a “reserved concurrency” on a Lambda; this setting acts as a max concurrency of a function.
Use tags and have a naming convention. E.g. add a “team” tag so you know which team to contact about a Lambda. This is useful when you have many, many functions.
Separate customers also get their own instances to run their Lambdas; they are isolated from each other.
By default functions don’t have access to resources in your VPC. You can add it to your VPC, but currently there is a cold start penalty. This penalty can be several seconds; which is a lot if the Lambda only takes a few milliseconds to run. So you probably should not put your function in a VPC if you do not need it.
With regards to execution: you are billed in 100ms blocks. So if your function takes 60ms to run, there is—from a cost perspective at least—no benefit in speeding up the Lambda.
If you want to debug your functions locally in VS Code and you have
the serverless framework installed locally, you can update your launch.json
file:
{
"version": "0.2.0",
"configurations": [
{
"type": "node",
"request": "launch",
"name": "Launch Program",
"program": "${workspaceFolder}/node_modules/.bin/sls",
"args": [
"invoke",
"local",
"-f",
"hello",
"-d",
"{}"
]
}
]
}
How do you organize your code? Don’t have a mono repo. Use microservices or at least a service oriented architecture. Give every microservice its own repo, along with code only used by this service.
Advice: give the service name the same name as the repo to make it easier to find things.
Organize functions into repositories according to boundaries you identify within your system.
How do you share code between Lambda functions? It depends. Within the same repo
you can use e.g. lib/utils.js. You can also create an npm package. Or create a
new service to provide the functionality.
When using Lambda, you’ll probably end up using more external services. The functions themselves are simple, but the risk shifts to the integration with the external services.
Another risk is the security. With microservices you have more control, but also more things to keep secure. And thus also more places you can misconfigure.
Combining those two: the risk profile for a serverless application is completely different from “traditional” applications.