Devopsdays Ghent 2019: day two
Table of Contents
Devopsdays Ghent is a two day event. These are the notes I took at this second day of the ten year anniversary edition of devopsdays.

DevOps beyond dev and ops — Patrick Debois
This is a story about busting silos and making new friends.
Patrick retired from organizing devopsdays five years ago. His next challenge was helping a company with their DevOps journey.
After about a year, DevOps was a thing at the company. The development and operations teams worked together and Patrick started to look for the next bottlenecks.
For a lot of things they used services instead of building things themselves (monitoring, etc). Patrick calls this “servicefull”: use a lot of services. Make the suppliers of the services your friends.
There was internal DevOps and collaboration, but they did not have the same communication with their suppliers. Communication works differently there. As a customer they used documentation, which is a way of communication from the supplier to the customer. To communicate back, they went to conferences, used Slack and reported findings. Suppliers welcomed this feedback since it is apparently hard to get. This feedback might even help developers make a case for an issue with their managers since there is now proven customer demand.
Patrick went to other departments of their own company next:
- Marketing
- Your biggest fans: each new feature means something new they can talk about.
- HR
- They have their own SLA: paying employees which, by the way, was something that could be automated.
- Sales
- These people have enormous pressure from the customer, the speed needed in deployment is the speed needed by sales. They also pressure engineering to make things more simple and not over-architect things.
- Legal
- They are like ops: nobody sees them unless there is a problem.
- Finance
- In a way they are testers: if there’s no money in the bank, you have failed. Although they play in the shadows, they enable you to do the job you like.
Unfortunately they could not convince enough customers to buy the product they made. The company shut down, but it was an awesome experience.

DevOps was not the bottleneck. You need the rest of the company; every part is needed to succeed.
By the way: the reason Patrick used horses on the slides? He learned that unicorns do not exist.
Pipelines to Production: Detangling the DevOps Web (of Lies) — Jody Wolfborn and Kimball Johnson
Creating a DevOps team does not solve your problems. You need trust, which you’ll have to earn. You can start earning that trust by automating things and showing that the automation is reliable and helps with the repetitive stuff.
You cannot just throw tools at it. You’ll have to find the right tools and keep evaluating your tool set.
By deploying small, iterative changes, and tracking and versioning them, it is easier to find out where the problem lies. Would you rather debug all changes made in a month, of just a small set of changes?

You don’t want to react to issues, you want to proactively monitor production to detect broken stuff.
Also make small, iterative changes to the processes. Include the rest of the organization.
DevOps is about communication. Breakdowns in DevOps are breakdowns in communication.
Fix breakdowns by communicating your needs, but mostly by listening to the needs from others and responding with empathy.
Different paths, same place - human case studies — Michael Ducy
The people are what makes this community so special. They have had a tremendous impact on Michael. There’s a diversity of … all the things: culture, language, background, etc.

Background is special in this list. It’s not something you are “born into.” Some people have a background of drug addiction, have been in prison or are high school dropouts. That does not mean they cannot be successful.
Have empathy: we don’t come from the same place and have not had the same opportunities.
Never criticize a person until you’ve walked a mile in their shoes.
The Perfect Storm - How We Talk About Disasters — George Miranda
Super visual outages can cause a lot of reputational damage to a company. You should contain the damage and prevent it from getting worse.
It is important to have a plan beforehand. Your plan should include the way things are coordinated between the different departments in case of a severe technical incident. This plan should be well documented and practised regularly.
When PagerDuty had a visible, multiple hours outage, there was a lot of chaos in the business instead of calm. While the engineering department was used to having and solving these kind of issues (albeit not on this scale), for the majority of the company this was new—which lead to chaos. Engineering needed to share how to deal with these kind of technical problems with departments like marketing, legal, PR, finance, etc.
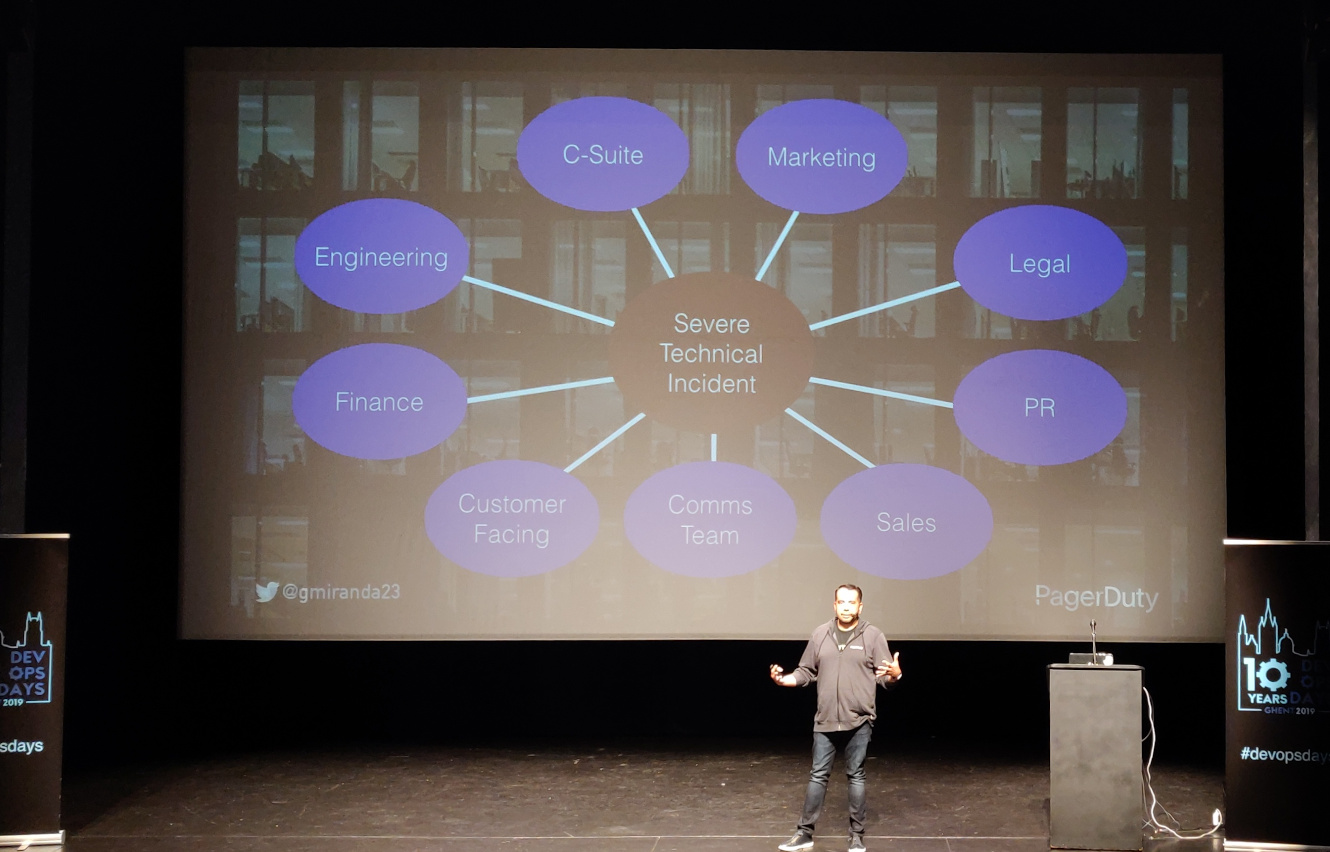
Most important takeaway: look at an incident response system, see for example the cut-down version of the PagerDuty Incident Response process. (Disclaimer: George works for PagerDuty.)
In case of a severe incident, the whole company should know what is happening in engineering. For example: the marketing department should stop campaigns, sales people should not try to live demo the system, etc. There needs to be a broad cross-functional response to the incident.
We often talk about a T-shaped individual: a person with broad knowledge but also a (single) deep expertise. When you put a lot of these individuals together, each person still has their own speciality, but the group as a whole covers a much larger area. With that in mind: DevOps does not really remove all silos, but we have learned to communicate better.
Where do we go from here? The fundamentals will stay the same, but the scope will be different. This is an opportunity to spread what we have learned as engineering to other parts of the company (and vice versa).
Engineering practices that make their way to other departments:
- Chaos engineering
- Blameless postmortems
- Adoption of retrospectives (also after practising an outage)
- Visiting other silos
There is an opportunity for us to learn more from the business. They are curious about learning and adopting practices from us. We should also be open and curious to learn from them.
More resources:
Sysadmin to DevOps: Where we came from and where we are going — Bryan Liles
We used to be able to save the day with some C or C++ code. In the nineties dev and ops belonged together. Somehow these two grew apart. Then we had a situation where parties were frustrated with each other: Why don’t developers understand networking or Unix/Linux? Why don’t sysadmins understand software that is more complicated than something in a shell script?

If we break the problem down, we have people that write software that solves a (business) problem. That software most likely runs on a server somewhere. You need a team to understand the full stack. We thought we had dev plus ops. But developers did not think about ops. Instead we had dev versus ops. With DevOps we are back where we started.
The good parts of DevOps:
- automating and removing manual failures, infrastructure as code
- empathy
- collaboration
- “little a” agile (not the certifiable, “big A” agile)
The bad parts:
- DevOps Engineers – you can do DevOps, not have DevOps
- SRE
Our progression:
- We learned how to automate all the things. (But we take ourselves too seriously.)
- We created new synergies (DevSecOps).
We’ve been doing this for 10 year now. It’s safe to say DevOps is no longer a fad. Dev{*}Ops might be still a fad. Time will tell.
DevOps, distributed — Bridget Kromhout
If you look at the number of devopsdays events, you can see quite a jump between 2015 and 2016. This is because in 2015 documentation was put up on the devopsdays website. Information on how to run such an event was made more accessible to others.
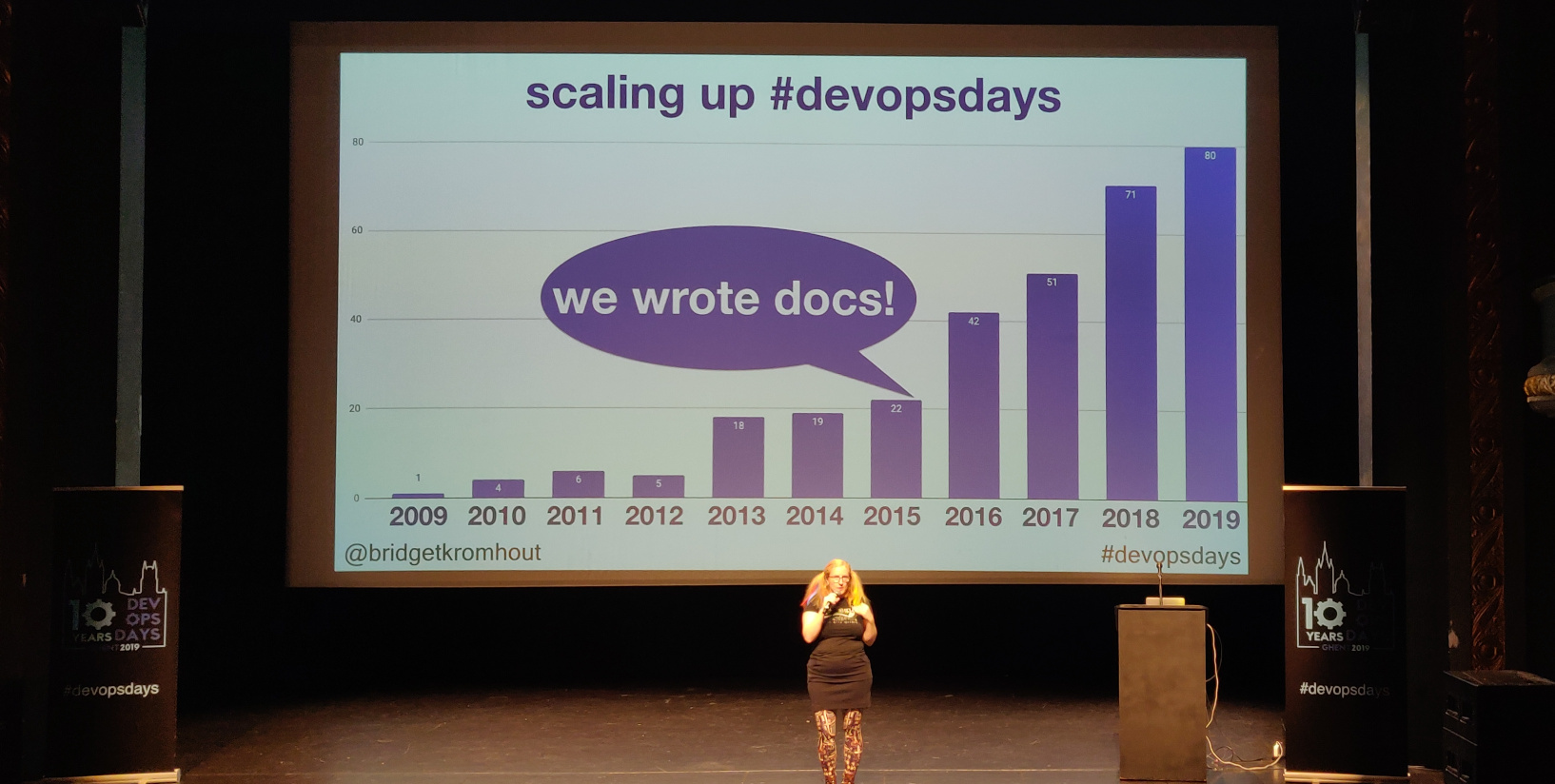
The main takeaway is that you can grow much more than you thought you could, if you put in the effort to allow others to do what you can do.
If you worry about the semantics of the word “DevOps,” you are are focusing on the wrong thing. Worry about impact instead.
Ignites
Ignites are short talks. Each speaker provides twenty slides which automatically advance every fifteen seconds.
Metatalk: An ignite about what I’ve learned giving ignites — Jason Yee

Some tips about ignite talks:
- Don’t introduce yourself
- No title slide, tell them directly what you want to tell, get straight to it
- The big challenge is the timing; don’t wait for your slides but keep talking and they will eventually catch up
- Don’t memorize your script, but get a feel for it.
- You will feel nervous, but that is okay. Everybody wants you to succeed.
- Remember the letters C,A,L,M and S: This spells “SCAML”: Spreading Culture As Messy, heavily indented text fiLes.
How Observability is not killing Monitoring — Blerim Sheqa
- Monitoring: black box
- Observability: look inside the box
Observability is not a replacement, it is an addition to your monitoring
The end
And that’s it for the devopsdays Ghent 2019 talks. Well… almost.
There’s one sheet I want to share. It’s not a great picture and out of context here (it’s one of the sheets Jason used in his ignite talk), but I think it’s a great way to close off.

Jason Yee with an ancient DevOps proverb: You don’t just do DevOps, you must feel DevOps