Devopsdays oNLine 2021
Table of Contents
Since COVID-19 is still around, devopsdays Amsterdam was an online event again. These are the notes I took while watching the talks.
![]()
How cognitive biases and ranking can foster an ineffective DevOps culture — Kenny Baas & Evelyn van Kelle
In practice, not all team members are treated equally although we might think they are.
How to make sure everyone said what has to be said?
In each team ranking takes place. It determines who takes the lead, who expresses an opinion, etc.
We need to make sure ranking is made explicit. Your job title or position in the org chart is explicit ranking. But things like your gender, skin colour and level of charisma are part of the implicit ranking.
The result of this ranking can be a situation like this: a woman on the team just explained something on a certain topic, but questions about it are addressed to the white man in the team.
We all have a list of traits we associate with higher rank. So if someone ticks more of those boxes, they are seen as higher in rank. You can also rank yourself lower compared to others. As a result you might not express your opinion because someone you regard as having a higher rank said something that conflicts with what you wanted to say.
The person with the higher rank should be aware of their rank and “share it.” Ask yourself the question “what don’t I know?” in a discussion. Ask the question the other (with a lower rank) is afraid to ask.
Own, play and share your rank.
How can we create and include new insights?
We use cognitive bias to make decisions. Usually this helps us, but sometimes it works against us. What we know hinders us from taking on a new perspective and it limits us in our thinking. We get stuck in what we know (functional fixedness).

Be aware of your biases and try to break free from them.
Who makes decisions and how to get everyone onboard with the decision?
Have less “corporate” meetings and more “campfires” where we share ideas and talk about the why.
There are 4 ways to go into a decision:
- Idea
- Suggestion
- Proposal
- Command
If you have a proposal or command, be open about it: “this is what we are going to do, what does it take to go along with it?” This is better than pretending it is completely open for discussion.
Getting Started: Embrace Your Inner Child — Rain Leander
Learning to ride a bike when you are older is harder than when you are a child. This is not so much a physical thing, but we do not want to be embarrassed when we are older. This goes for everything new we do: we want to be the best—instantly. However you will fall down and fail. You will make mistakes. Embrace that, be brave and learn.
Bravery is something you have to develop. It is hard! And it is not a lack of fear, it is moving forward despite of fear.
The steps to become more brave that worked for Rain:
- Embrace vulnerability
- Admit you have fear
- Do it anyway
- When you fall down, get back up
Play!
Playing is instrumental to life. No one can tell you how to play. Do what is fun for you. And when it stops being fun, just stop doing it. Book time in your agenda to play, each day! (And napping counts.)
Explore! Some of the things Rains uses to stay curious and explore:
- Listen
- Ask questions
- Avoid assumptions
- Listen
- Embrace learning as fun
- Develop a beginner’s mind
- Listen
You are a unicorn. Your experience, your background, your education, etc. makes you unique.
Be willing to fall down, and get back up. Be brave. Play! Conquer the world.
(The original blog post for this talk: Getting Started: Embrace Your Inner Child)
Prevent Heroism: How to Work Today to Reduce Work Tomorrow — Quintessence Anx
We might be familiar with “the angry sysadmin.” It is the person who is highly skilled, has lots of knowledge, gets asked all the questions and puts in overwork to get their own work done. This is basically the description of the character Brent from the book The Phoenix Project.
Being a Brent-like person is stressful and may result in anger, resentment and strained relationships. Brent-like persons typically have issues with things like time management, maintaining focus and allostatic load (where you’re too tired to be awake and too stressed to sleep). But there are business implications as well: diminishing returns, high turnover, reputational damage and financial performance goes down.
Instead of having—or being—a Brent-like person, we rather want no silos and no vacuums (the latter is where you, for instance, get no response to questions).
Steps to get out of this situation and do things different:
- Brainstorm the work (every task done during the day, planned or unplanned)
- Determine which “stream” each task is in: reactive or proactive
- Look for patterns
- Switch to “upstream mode” to prevent work in the future (short term/long term vs permanent/temporary matrix)
- Plan and Prioritize work: upstream work is more important
- Do the work
- Iterate (what works, what does not, what can be improved)
Upstream work is the proactive and preventative work that reduces the need for reactive, or downstream, work
But how does one measure things? Things to keep in mind:
- What are your needs?
- Learn how to measure them
- Establish baselines
- Know your capacity
- Track the rate of change
- Set goals
- Iterate

Slides and additional resources can be found at https://noti.st/quintessence
Real-world Continuous Delivery: Learn, Adapt, Improve — Michiel Rook
This talk is a real life case study, focussing on the deployment of the platform of a customer of Michiel.
There was a pretty long release check list with manual steps. Especially when under pressure steps were forgotten or done incorrectly. Ideally they released every two weeks (after each sprint). It took a team 2–3 days of manual work. Time not spent on features.
To improve this situation, the following goals were set:
- Reduce costs by letting people do more valuable work
- Faster feedback and ability to do more experiments
- Reduce toil
For continuous delivery to work, you have to make things small. This is a key difference between high and low performing teams (see Accelerate).
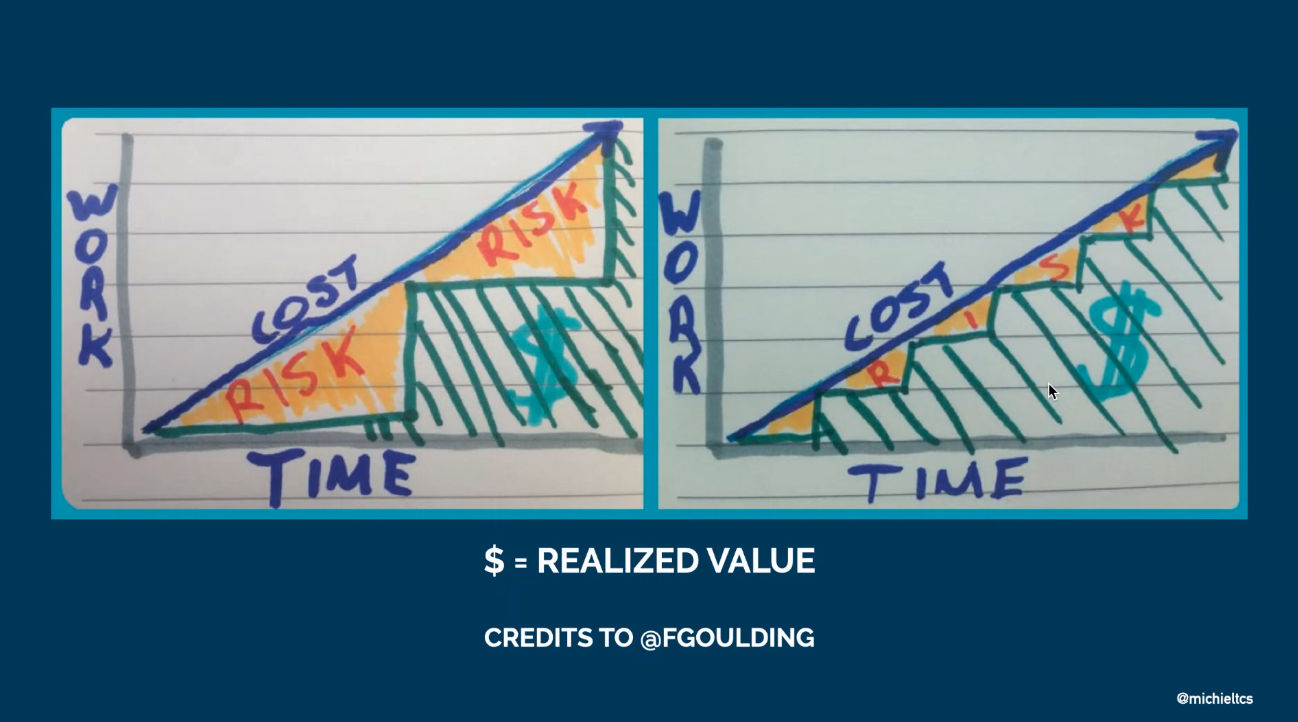
Although the platform was a monolith, they deferred splitting it up. If they would have broken down the monolith into smaller pieces, they would have more manual steps for each release and made the situation worse. So the strategy was to automate first and then split.
Phase 1
The teams increased the release cadence. They switched to a weekly release cycle instead of a release every two weeks (on good weeks). Releasing more often makes problems visible faster.
The release process was also automated. They created a pipeline to build and deploy the platform. In this phase there was still a manual step between the deployment to acceptance and production. They didn’t trust the system enough yet.
They also made changes in their way of working. The big one: pair programming. This is superior to code reviews, for example because you also discuss code that does not get written and you have architecture discussions.
Other changes:
- A “do not leave broken windows” mentality. This is from the book
The Pragmatic Programmer)
which states:
neglect accelerates the rot faster than any other factor.
- Measure how they were doing in terms of their continuous delivery journey. The book Measuring Continuous Delivery has useful information about this.
Phase 2
In the next phase they had a robot press the button to deploy to production. This required zero downtime deploys. They solved this by doing rolling updates (a load balancer in front of a couple of backend servers and then upgrade one server at a time until they are all up-to-date).
Pipeline failures come in all forms, e.g.:
- Flaky tests
- Timeouts
- Network stability issues
- External dependencies in tests
If you cannot trust a test, remove it. Otherwise you’ll probably work around it, which is more dangerous.
This level of automation also meant they treated pipeline failures as priority 1 issues (which warrants extreme feedback to notify people of a broken build: lights, sounds).
Phases 3
In the third phase they made it faster:
- Scale vertically and horizontally
- Parallelize tests
The Adjacent Possible: Evolution, Innovation & Catastrophe — Jason Yee
The four cornerstones of resilience:
- Monitoring: knowing what to look for
- Responding: knowing what to do
- Learning: knowing what has happened
- Anticipating: knowing what to expect
The term “adjacent possible” comes from biology in the context of evolution. Evolution requires a chain of changes to happen.
Complex systems usually do not have a single root cause, only contributing factors. Perhaps there’s an “adjacent possible” of failure. We cannot anticipate all failures, but perhaps we can explore them.

How do you explore adjacent possible failures?
To move from known knowns to known unknowns, we can use chaos engineering
(thoughtful, planned experiments to improve our understanding of how systems
work (and fail), so that we can improve them
). This way we can explore the
known unknowns and these then become the known knowns. From that standpoint,
the original unknown unknowns become the known unknowns.
Scientific process:
- Observe (what is normal)
- Hypothesize (how do we think it will react to failure)
- Experiment (inject failure)
- Analyze (what did actually happen)
- Share knowledge
Explore the adjacent possible!
Minimal viable presentations — Mark Smalley
There are four important points to take into consideration when creating a presentation:
- Accept that it is not about you
- It is the audience’s presentation. What you want to tell might not be what they want to hear. Kill your darlings.
- Anticipate silent questions
- These questions are:
- Huh? What is he talking about? (Solution: be clear about the self evident stuff)
- Really? (Solution: be clear about the evidence)
- So? How is this relevant for me? What’s in it for me?
- What’s next?
- Think of learning objectives
- Think about what the audience should know, believe, be able to do and feel after the presentation.
- Dare to choose your ideal audience
- Accept that the presentation will not be for the majority of the people listening.

Mark Smalley applies the advice given in his talk to this talk itself
Engineering Metrics That Matter — Dan Lines
Before we dive in, let’s start with some KPIs you want to avoid:
- Lines of code
- Number of commits
- Individual stack ranking
- Anything with story points
So what do you want to measure? What will improve your process?
- Couple pull request size with cycle time (how much time from coding to deployment)
- What you’ll see is that bigger PR size takes longer to review and thus increase cycle time.
- Deployment frequency
- How often can we get new value into the hands of customers.
- Idle time
- Waiting for e.g. a release or review. Waiting means context switches which means less productivity.
- Code churn
- How much code are we reworking in a short period of time? High code churn indicates delays and quality issues.
- Review depth
- The amount of feedback per PR.
- Mean time to restore
- How long it takes to fix an incident in production.
- Investment profile
- New functions for our customers vs bug fixing, backend or non-functional work.
DevOps is no Walk in the Park — Sabine Wojcieszak
In a park you are safe, you do not need a map, can wander where you want and you need no preparation. DevOps is not like that.
The term CALMS has been coined by John Willis to explain DevOps. It stands for:
- Culture
- Automation
- Lean
- Measurement
- Sharing
Most people talk a lot about the automation and some about the measurements part, but very few about sharing and even less about culture.
There is a similarity with Agile where the term began as a niche but became hyped and then mainstream, where people talk about Agile without knowing what it is. We should prevent this from happening with DevOps.

It’s no longer business and IT, but IT is part of business. One could even say IT is business.
DevOps is not cherry picking what we like (automation) or only picking the low hanging fruit and calling it “DevOps.” It needs an holistic approach. But this needs a lot of ingredients. In the right mix.
You should always ask yourself why you are doing DevOps. Do you think it is cheaper because of the level of automation? Because everyone is doing it? To deliver better software?
You need to understand the whole approach.
DevOps means to Sabine: deliver valuable products with better quality sooner to
customers/users.
This means we need to know what is valuable for our customers,
what our customers think of as quality, etc.
The term CI/CD in context of DevOps traditionally stands for continuous integration / continuous delivery. But it could also stand for continuous improvement / continuous development, if we think of products and people. But we can also talk about continuous improvement and continuous discovery of opportunities and outcomes.
You cannot buy DevOps—neither with tools, nor with certifications. But it’s not for free either. You will fail for example.
Some anecdotes of where it went wrong:
- “We are now the DevOps department.” Which means there is still a silo with a lack of communication.
- “We have a DevOps team that is setting up the pipelines.” Again no communication, no transparency.
- “We have a linter but it gave to many warnings so we turned it off.” No understanding about why it is done, no trust that it helps to grow, sign of fear to make mistakes.
- “We are measured by the number of developed features, but not allowed to talk to sales.” It’s a feature factory, measuring the wrong things. Again also not enough communication and silos.
- “IT has not reported any problems.” Be open to the obvious: if customers complain, there is a problem. Ask yourself what is actually monitored? Not business relevant metrics obviously otherwise the problem would have been detected by the company instead of the customers.
DevOps is more than automation, it is CALMS.
If you don’t get the C then don’t bother with the A, L, M or S.