FOSDEM 2026
Table of Contents
January is already almost over, so time for FOSDEM,
the yearly free event for software developers to meet, share ideas and
collaborate
in Brussels. Last year I
focussed on the Go track, this year I selected a mix of security and Python
related talks to attend.
Streamlining Signed Artifacts in Container Ecosystems — Tonis Tiigi
It’s possible to sign Docker images, but at the moment most are actually not signed. Also, users should understand what the signature is protecting and what it’s not protecting. We should not want signing just to tick a box on the security checlist, but because of the security it adds. And we need something simple: integrated with existing tools, should not slow down tools.
Buildkit powers “docker build” but is not limited to Dockerfiles. It’s high
performance, can build complex builds and has caching.
A modern build is a graph of images, Git repositories, local files, etc. The results are images, binaries, archives.
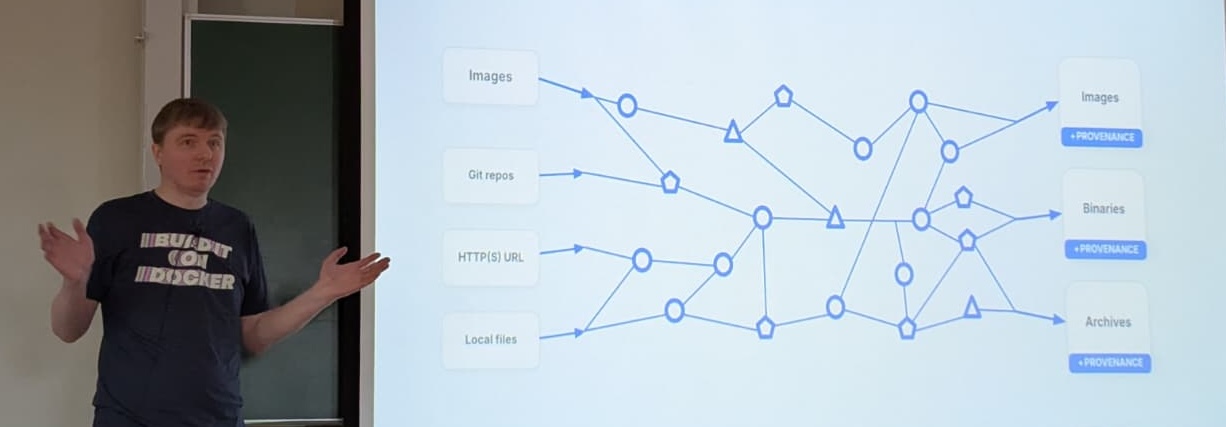
Tonis Tiigi explaining that builds of modern software are a complex graph
We need Supply-chain Levels for Software Artifacts (SLSA) provenance: what has actually happened in the build? What was the build config? Et cetera. It’s useful to figure out how an artifact was built.
Buildkit does not sign images by default. GitHub has an example in the
documentation
to run a build with Buildkit and generate an artifact. It claims to generate an
unforgeable statement
. But if your GitHub credentials are
leaked and the attacker can get your hands on the temporary signing key, they can
use it to sign their own artifacts.
Docker created the github-builder
repository. It contains reusable GitHub Actions to securely build images. If you
use this, your images are signed to prove that they were built from a certain
repository, using the configured build steps. Where Buildkit (among other
things) provides isolation, github-builder provides signing context. It also
protects against build dependency leaks.
So that takes care of the signatures, but how do you verify them?
- The command “
docker inspect” now shows verified signatures - You can manually verify it with cosign
- You can also use sigstore/policy-controller for Kubernetes
Buildx also includes experimental Rego (Open Policy Agent) policy support. This
means you can write a matching policy for Dockerfile, e.g. Dockerfile.rego,
which is then automatically loaded. All build sources now need to pass policy
for the build to continue (images, Git repositories, URLs, etc).
You can do very complex stuff in the policies. As simple example Tonis showed:
package docker
allow if {
input.image.repo = "org/app"
docker_github_builder_tag(input.image, "org/app", input.image.tag)
}
This policy should make sure that the image can only be built from this repository and that the image tag should match the Git tag.
Summary:
- No reason not to sign
- Not all signatures are equal
- Software pulling packages should verify pulled content
Sequoia git: Making Signed Commits Matter — Neal H. Walfield
Version control systems (also known as VCSs) track the following:
- Changes to the code
- Authorship
- Other metadata
- Commit message
But the author can be faked: the metadata is set by the author, including the
author’s name. After a quick “git config” command you can commit as anyone you
want, for example Linus Torvalds.
Sure, GitHub could see that the committer (the one pushing the commit) and
author are different. However, this is not necessarily bad because we might
simply want to give proper attribution to the author of the commit.
And in theory the forge might also be compromised, or someone may have gotten permission to push to the project.
To prevent impersonations, we can cryptographically prove who the author is by signing the commits. But now the problem shifts to the certificates. Because anyone can create a key with any name (again, for example Linus) attached to it. So what does a signed commit mean now?
How can we be sure that the author is who they say they are? There are ways:
- You could talk to developer the verify
- You could go to key signing parties
- You can use a central authority that you trust (e.g.
keys.openpgp.org, the Linux developer keyring,
the
distributions-gpg-keyspackage, or, if you trust Github, usegithub.com/<username>.gpg)
You can use the following command to show the Git log and the signatures on them:
git log --show-signature
But now you need to actually check that the signatures are indeed made by the certificates you trust.
It’s up to the maintainers of the software to curate a list of contributors and track when contributors join and leave (yes, there is a temporal element as well). This is hard. Maintainer needs tooling. And you would want to detect unauthorized commits (impersonation, a malicious forge, a machine in the middle or for instance when project is given to a new maintainer by a forge/registry).
What does the solution look like?
- Clear semantics
- The project itself maintains signing policy
- Third party uses maintainers’ policy to authenticate project
- Verification, not attestation: do not rely on any external authority
(Note that the maintainers can still be socially engineered to include the key of an attacker in their policy. So they still have to be careful about who is added to the policy.)
Sequoia git provides:
- Specification
- Config
- Tooling
With Sequoia git (which part of
the Sequoia PGP project) you can have a signing
policy in an openpgp-policy.toml file in the project’s Git repository. It
specifies users, their keys and their capabilities. You can use sg-git to help
maintain this file.
For instance to add user Alice and then describe the current policy, you can use the following commands:
sq-git policy authorize alice --committer <cert>
sq-git policy describe
A commit is “authenticated” if at least one parent commit says the commit is acceptable (via the policy). To verify that there is an authenticated path from the current state back to a certain commit we trust, use this command:
sq-git log --trust-root <sha of trusted commit>
Projects may have contributions from others that are not included in the policy.
To maintain an authenticated path when accepting the contribution, a trusted
author needs to merge the contribution via a merge commit that is
authenticated. (You may need to use the “--no-ff” on the merge to make sure
there is a merge commit though.)
An Endpoint Telemetry Blueprint for Security Teams — Victor Lyuboslavsky
With open source we can inspect something that is broken, we can change the defaults. With security we are used to the opposite; it’s a black box. We are not used to owning the data. The data exists on the endpoints, but ownership is transferred to a different team. How can we add more security in a way engineers understand and can use?
Victor presents a blueprint with the following layers:
- Endpoint agents
- Control layer
- Ingestion, streaming & storage
- Detection
- Correlation, intelligence and response
The value is not in the layers themselves, but the boundaries. For example, the ingestion should move the data reliably but should not care which tool collected it. This makes them loosely coupled.
For endpoint agents Victor suggests osquery which allows basic questions about endpoints. Data is structured and consistent. It aligns with open source values. (Alternatives: scripts & cron, log shippers like filebeat or tools like auditd or Event Tracing for Windows.)
Controlling the data (the next layer) means that you want to have:
- Central config
- Live queries
- Consistent schemas
Fleet (disclaimer: Victor works here) is
built to manage osquery at scale and a good candidate for this layer.
The control layer needs to work hand-in-hand with ingestion layer. The ingestion layer moves data to downstream system. E.g. Vector or Logstash can be used here.
Ingestion isn’t where you get clever. It’s where you get reliable.
Streaming decouples users from consumers and e.g. allows replay. Note that this is an optional step and it would come after ingestion, not in place of it. For instance Apache Kafka can be used in this layer. Ingestion absorbs the mess. Streaming preserves flexibility.
The storage layer is where telemetry becomes durable. It’s about being able to ask hard questions later. Examples of useful tools: ClickHouse, Elasticsearch (which is better at text search) and Iceberg (which is slower for active investigation).
For the detection layer you might want to use Sigma. It provided portability. Rules are translated to native SQL running on ClickHouse. Intent (Sigma signatures) becomes execution (SQL query to get the data).
Finally the correlation layer: Grafana can be used for correlation and visualisation. Grafana can query ClickHouse. Grafana also has alerting.
Note that response isn’t just about automation. It’s also to pause and ask better questions. The correlation layer should focus on enabling humans to act.
Open endpoint telemetry is not an “EDR killer”. It does not replace it. It adds diversity and complements other tools. It provides a second set of eyes.
The Bakery: How PEP810 sped up my bread operations business — Jacob Coffee
Python loads imports eagerly by default. This leads to memory bloat and cold start issues. Explicit lazy imports (see PEP 810) only import a module when it’s first accessed not when the import statement is executed.
Lazy import is scheduled to be included in Python 3.15 and looks like this:
lazy import foo from bar
The design principles applied are that lazy imports are:
- Explicit
- Local
- Granular
When parsing the Python code a proxy module is created. Only when the module is actually used, the proxy is transparently replaced by the real package. You will not always see improvements, so do not blindly replace all imports with lazy imports.
PEP 810 also eliminates the need for TYPE_CHECKING guards. (See the typing
docs, in
short: importing a module that is expensive and only contains types used for
type checking in an “if TYPE_CHECKING:” block.) It also helps for faster test
discovery and collection, less memory usage, decrease cold start slowness in
e.g. AWS Lambda functions, CLI applications, etc.
Meta (with Cinder) saw a 70% startup time reduction and 40% memory savings. PySide has a 35% startup improvement.
About CLI tools: when using lazy imports you might notice the difference when
using --help. There’s no need to load all dependencies to just output the help
text of a tool.
Some notes:
- Import time side effects (e.g. logging configuration, DB connections) are also delayed!
- Type checkers need to be updated
- Import errors move to first use (so in runtime, not at launch). Keep that in mind when debugging
- It’s not always faster, so profile your application before migrating and see where you can potentially benefit
- Document your lazy imports!
- You cannot do lazy imports in functions
Circular imports are probably still a problem, but they just show up later.
Link to the repo for this talk
Modern Python monorepo with uv, workspaces, prek and shared libraries — Jarek Potiuk
Jarek is, besides his other roles, the number 1 Apache Airflow contributor. The Apache Airflow repo is the monorepo he talks about today. There is also a series of blog posts about this topic: see part 1, which links to the other parts.
Airflow drove early requirements for uv workspaces. They now manage 120+ distributions seamlessly with it. It allows them to combine distributions to work together in a workspace. Also used to import from one distribution in another one.
The project shares a single virtual environment used by uv in root of project.
If you run “uv sync” from the top level you get everything. If you run it in a
subdirectory (e.g. airflow-core) you only get what is needed for that
distribution.
Benefits of the uv workspaces:
- Isolated
- Explicit
- Flexible
Hatch has (or will have, at the time of writing) largely compatible workspaces.
However pre-commit became a bottleneck. They needed to run 170+ pre commit hooks on every commit. Prek is drop-in replacement for pre-commit and works fantastic. It is optimized for speed and monorepos.
Airflow uses symlinked shares libraries (where a shared lib is also a distribution). The Hatchling build backend needs to replace links with physical copies during packaging. They use Prek to maintain consistency.
uv sync detects conflicts between merged requirements files and Prek hooks
enforce relative imports in shared code to prevent cross coupling issues (IIRC)
PyInfra: Because Your Infrastructure Deserves Real Code in Python, Not YAML Soup — Loïc “wowi42” Tosser
Loïc is a Frenchmen (which, as he himself states, means he must have opinions) and not a YAML fan to put it mildly. That is: YAML as a programming language, e.g. how it is used in Ansible.

Loïc Tosser demonstrating what happens when you ask a config file to be a programming language
PyInfra is an infrastructure as code library to write Python code which is then translated to shell scripts to run on the target hosts. So, in contrast to Ansible, you do not need Python on the target. The target machine only needs SSH and a POSIX shell. You can also configure Docker containers with PyInfra.
If it has SSH, PyInfra can talk to it.
PyInfra has idempotent operations and built-in diff checking. Declarative infrastructure with actual code and not YAML. You can use inventory from Terraform, Coolify or any API.
You can leverage the entire Python packaging ecosystem. Slack integration? Just use the right Python package.
PyInfra is not only a CLI tool, you can also use it as a library.
PyInfra is 10 times faster than Ansible, uses 70% less code, has proper code
reuse via import and proper loops instead of with_items. It can have actual
unit tests and can scale to thousands of servers. Also you no longer have error
messages stating that the error appears to be in … but may be
elsewhere in the file …
(looking at you Ansible). PyInfra has
clear error messages without having to specify -vvvv and wading through
hundreds of lines of output.
The suggested migration path:
- Start small, one playbook at a time
- Use your IDE for autocomplete and refactoring
- Leverage Python’s standard library and the ecosystem with all its packages
- Sleep better because you don’t have to debug at 3 AM.
Is PyInfra production ready? Yes! It has a stable API, is already in use in production, it’s actively maintained and is MIT licensed (so no commercial entity behind it to steer its direction).
You can get started today with a simple “pip install pyinfra”.
(Note from me, Mark, I found Loïc a great speaker: he has lots of energy, is funny and can transfer his enthusiasm to the room. If the topic interests you and the video becomes available, I would recommend watching this talk as a great sales pitch to get started with PyInfra.)
Ducks to the rescue - ETL using Python and DuckDB — Marc-André Lemburg
ETL stands for Extract, Transform, Load. Nowadays we usually do Extract, Load, Transform because databases are efficient in processing.
DuckDB is open source, in-process analytics data storage (OLAP). It is similar to SQLite, but for OLAP workloads. It has great Python support and uses SQL as standard query language. It’s pip installable, column based (Apache Arrow). It’s single writer but allows for multiple readers, so it’s not a distributed database.
Polars’ streaming can help with processing your data as a line-by-line stream so you don’t have to load the whole file in memory at once.
Example to load a CSV file into DuckDB extremely fast:
SELECT * FROM read_csv(...)
You can load the data into staging tables first to prepare everything and not mess up e.g. existing data. You can then transform data in DuckDB, e.g. filter out unneeded and duplicate data, validate data, fill in missing data, convert data types, etc. You can do the transforms in SQL. You can even use native integrations to write to PostgreSQL, MySQL, etc. Or worst case stream to Python.
Guidelines:
- Know your queries, that is: know how your data is going to be used
- Use the Pareto principle (80/20 rule): optimize for queries that are used often
- Keep a healthy balance between performance and space requirements (which are often trade-offs)
Huge datasets: use the DuckLake extension.
To get started: “uv add duckdb”. Do some experiments and see how it works for
you.
My takeaways
- Yes, FOSDEM is crowded and you may not be able to get into every talk you want to see in person, but it’s still nice to be there. It’s well organised and there’s a friendly atmosphere. Lots of interesting projects to see and people to talk to. And it’s convenient if you want to sponsor your favorite projects by buying some merchandise.
- It’s worth investigating signing Docker images (in the right way) further.
- Lazy imports look useful! Once Python 3.15 lands it’s worth doing profiling on the projects I work on to see if we can use those to speed things up on startup and save some memory.
- At work we recently decided to go for a monorepo for a project. I want to see
if/how
uvworkspaces andprekcan help us. - I’ve written a bunch of Ansible roles to configure my humble homelab and laptop. Perhaps it’s time to switch to PyInfra? It sounds promising and might be worth the investment of migrating to.
About the trip
The Atomium at night
This year I had more time, so I booked a room at Falko Hotel for two nights. It’s about a 20–30 minute drive (depending on traffic) to the parking garage I used. And from there about 20 minutes with pubic transport to the Université libre de Bruxelles.
Staying another night meant I had more time for sightseeing, had the time to write this post from my notes and could drive home well rested the next day.
As for tech: besides a phone and laptop, I also brought along two items that made the trip more comfortable:
- A MOJOGEAR Mini Evo powerbank to give my phone extra juice to make it through the day. With 10.000 mAh and up to 22.5W of power it’s more than sufficient for a day at a conference. With its small size and less than 175 grams in weight, it’s also easy to carry around.
- A GL.iNet Opal (GL-SFT1200) travel router. I plug it in, hook it up to the hotel internet, start a VPN connection and all my other devices automatically connect to it and can use the internet without the hotel snooping on my traffic. (Not that I have an indication that my hotel would do that, but theoretically they could if I would not use a VPN.)