AI Engineer Europe 2026: Workshop Day
Table of Contents
AI Engineer Europe is “Europe’s first flagship AI Engineer event”. I was fortunate enough to be one of the engineers that Schuberg Philis (my employer) sent to this conference. The first day was workshop day.

How to Build Agents That Run for Hours (Without Losing the Plot) — Ash Prabaker and Andrew Wilson
Why are agents losing the plot?
- Context: the agent can’t carry state (and has “context anxiety” if the context is getting filled up)
- Planning: general models are not great at planning (e.g. running out of context)
- Verification: models are bad at evaluating their own output (it thinks it’s done)
There are two ways to fix this:
- Train the model
- Wrap the model in a harness
Anthropic’s new models were also combined with harness improvements last year. Every release of Claude could run longer unattended.
Harness design for long-running agents. Building the generator/evaluation loop, and then deleting half of it when the model caught up. Splitting up the generator (which builds the thing) from the evaluator (which grades the thing). Most people now use the same instance to build and evaluate.
Tuning a standalone evaluator to be skeptical is tractable. Making a generator self-critical is not.
Added one more role: plan (a 1-line prompt to full spec). This is the input for the generator. If you squint a bit, you’ll notice that this mimics the real world where we have a product manager (the plan role), an individual contributor (the generator) and a QA person (the evaluator).
Before any code gets written, the generator and evaluator negotiate what “done” looks like for this chunk. They iterate via files until they agree (one agent writes, the other reads and responds). The agents agree on a contract. This bridges user stories to testable behaviour.
Ash presented an example where a solo agent built a game vs building a game with a full harness. The solo agent was done in 20 minutes, and the full harness took 6 hours. But the result was significantly better and more thought through.
Out of the box, Claude is a poor QA agent. It would find a bug and then decide itself that it wasn’t a big deal and approve the work anyway.
With Opus 4.6 half of what was described about harnesses became obsolete. The new model needs less scaffolding and the harness can be less complex.
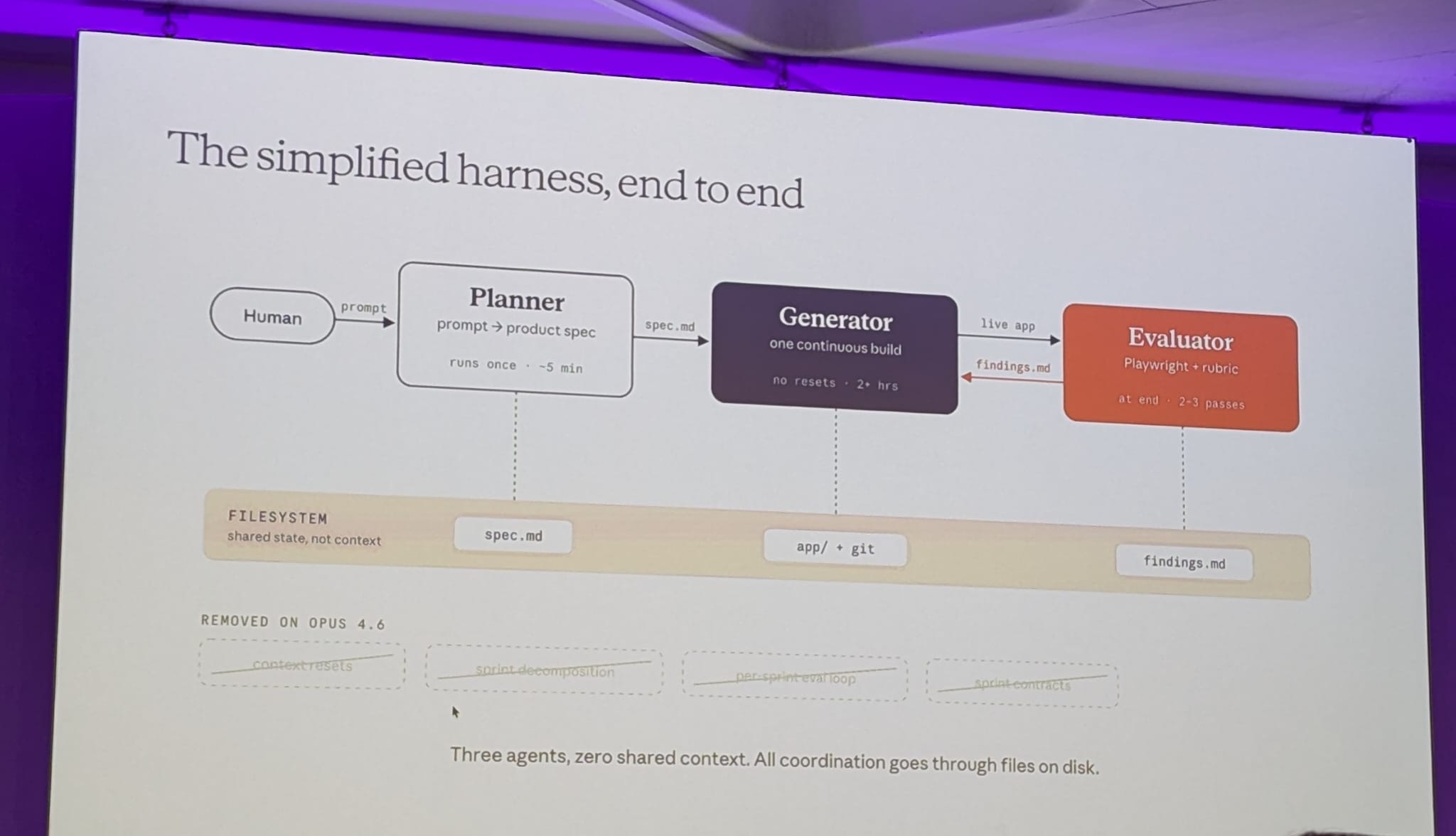
The simplified harness where the human prompts the planner, the planner writes the spec and the generator and evaluator work on the application
Takeaways:
- Use an adversarial evaluator, self-evaluation is a trap
- Structured handoffs are better than compaction
- Make subjective quality gradable with rubrics the model can apply
- Read the traces as they are your primary debugging loop
- Delete scaffolding where the model catches up
The models you are using (e.g. Opus for planning and Sonnet for building) influence the harness. The harness patterns that work tend to get absorbed back into the tools. Most of the loop described is buildable in Claude Code right now with primitives that are already available.
Further reading on the Anthropic Engineering blog:
Building Your Own Software Factory — Eric Zakariasson
Eric spoke about his experience using Cursor to build a software factory. Some parts are running autonomously. It’s hard work. These are his observations.
There are several levels of using AI. At the lowest level you have autocomplete. Then you progress to a coding intern, a junior dev, a developer (where the majority of code is written by the AI tool) to a senior developer and finally a software factory where the AI is a black box and operates like a dark factory.
Why would you want a factory:
- Throughput (24/7, machines do not need sleep)
- Consistent output (like an actual factory, but with AI there is a risk of losing determinism)
- Leverage your taste better
What do you need to build a factory?
- Primitives & patterns (co-located code and usage patterns)
- Guardrails (you want to let the agents free, but not too free, think about rules, hooks and tests)
- Enablers (what can you allow the agents to do to be more free, think about skills, MCPs)

Eric Zakariasson speaking about what you need to build a software factory
Rules should be created dynamically: if you see an agent doing something you don’t like, write a rule. Note that agents will behave better over time with newer models, so rules may become obsolete.
Other aspects you’ll need:
- Runnable: can the agent start the env?
- Accessible: can the agent use the tools it needs, e.g. Datadog?
- Verifiable: can the agent perform check itself?
For each of the different stages of the software development lifecycle you will need an agent. For example to review changes and automated testing.
You need to shift your way of working:
- You’ll write less code yourself (if any) but are managing your agents
- You are also going from sync to async
- You need to think more about scope and parallelising work (e.g. running some tasks in parallel will guarantee merge conflicts while other tasks do not interfere with each other).
- You still need to know how data flows and what users want
- You’ll want to identify the human in the loop. Is there e.g. a copy/paste action the user is doing now? Automate that away.
Since agents will run for longer periods, you need to trust them more. You get to know the agents: their weaknesses and their strengths and how to prompt them.
When having agents work in parallel, Eric is using separate environments (even in different VMs) to have reproducible and isolated environments without side effects from other branches and ongoing work. This will take more effort to setup, but once you are there, it is easier to scale up the number of agents working on your code.
You need to keep an eye out for where the agents go off the rails. Use this information to improve the factory.
Now how do you go from 5 agents to 100? Same as before: observe the outcome. And:
- Make sure the agents can verify their own work
- Setup automations. Examples:
- Eric demonstrated asking the agent what actions he does frequently so he can work on automating those
- Review the comments made on PR reviews so the agents can learn from them
- Move up abstractions
The takeaways:
- Be clear about your intent: what problem are you solving?
- Stay in the loop for important decisions (e.g. which payment system to use, etc)
- Build systems and tools: codify them and give your agents access to them
- Store context for later and keep it up-to-date (since it will evolve)
- Let the agents be free (one team had even given the agents a place to complain and that proved to be very useful)
Build Your Own Deep Research Agent + Technical Writer — Louis-François Bouchard, Paul Iusztin and Samridhi Vaid
The team built a multi-agent pipeline to replace the research and technical writing process. They give a topic and it will write a technical article (without slop or hallucinations). It targets short content, like LinkedIn posts.
The GitHub repo of their project: iusztinpaul/designing-real-world-ai-agents-workshop
Constraints:
- Costs per task
- Latency
- Quality
- Compliance & data privacy
There’s a scale from simple prompts (where you have more control and less costs) via workflows to single agent to multiple agents (where you have more autonomy, and thus less control, and higher costs). It’s best to always use the most simple solution. For example: if the context is known at or before query time and has less than 200K tokens, a simple prompt can suffice, using Context Augmented Generation (CAG).
In a situation where the context is not known beforehand (e.g. because it is private or too recent), you might benefit from including a workflow. (A workflow is a sequence of fixed steps, with the same steps in the same order each time). Think about using Retrieval-Augmented Generation (RAG).
The next step is when you need the system to take autonomous actions or you need dynamic behaviour. Then you get to agents, which can react to what is happening. These agents can use also tools, which can have their own:
- System prompt
- Validation logic
- LLMs
Tools are specialists, but with one shared decision maker which has a global context. Delegation to tools helps with context management. The tools can have their own context windows.
AI products are never just agents, simple workflows or LLM calls and tools. They combine all of them. AI engineers need to understand how to build these complex systems. And deep research systems are a perfect project on how to learn these complex, multi-agent systems.
The MCP server they built (see their GitHub repo):
- Tools: actions the agent can do
- Prompts: instructions the agent can follow
- Resource: data the agent can read
Why both skills and MCP? They are moving to using skills more, but those cannot replace the MCP server completely because some tools are too complex to be turned into skills.
LinkedIn post generation:
- Guidelines: what to write about (topic, angle, etc)
- Profiles: how to write (structure, terminology, character of the post)
- Research
Debugging workflows/agents purely through logs is hard. You want traces (LLM/tool calls with full I/O + metadata), latency and cost tracking. They used Opik for observability.
You also want to automate evals. Generating one post allows for manual review, but when scaling to 100 posts, it’s quite impossible to manually review each one. One small change could break something completely, so you need to review.
They used a three layer architecture:
- Optimization
- Regression testing (evals in CI/CD)
- Production monitoring (using Opik)
They encourage us to run their project ourselves and reading the code to understand the details of what’s going on.
AI Coding For Real Engineers — Matt Pocock
To follow the workshop along, see Matt’s workshop at aihero.dev/s/ai-2026.
Before I begin with my notes: this session is definitely worth watching (again) once it’s available on YouTube! Matt is an excellent teacher, has great energy and great content as well.
Once there are about 100K tokens in the context, the AI starts to get dumber and making increasingly dumb decisions. We don’t want the AI to bite off more than it can chew, so keep your tasks small.
Matt Pocock explaining about the smart zone / dumb zone
Even with the 1M context window of Claude the “smart zone” is still around 100K. Claude basically just expanded the dumb zone. Good for retrieval, less good for coding.
So how do you tackle big tasks? Multi-phase plans are a common solution. It’s basically a loop. This is where the Ralph Wiggum loop comes from. Matt likes something smarter though.
Every session starts with a system prompt. If you have 200K tokens in here already, you are in the “dumb zone” from the start. To stay in the “smart zone” you can clear the context. This does mean that you lose everything that happened after the system prompt. Alternatively, you can compact.
If you show the number of tokens in the status line of Claude Code (or whatever
tool you are using), you know how close to the “dumb zone” you are. When using
/compact it squeezes all information. The downside of using /compact over
/clear: with the latter you have a deterministic state.
The /grill-me skill (source)
is a really nice way of taking inputs from the world. It can
interview
the user relentlessly about a plan or design until reaching shared
understanding (according to the skill itself). Ideally you use
the /grill-me skill with both the developer and the domain expert in the room.
After the /grill-me skill, you want to summarize all those valuable tokens
into a Product Requirements Document (PRD). This is the definition of done for
your agent. You can use the /write-a-prd skill
(source)
to write this document. Note that there are testing decisions in there too.
These are important!
Matt explains that he does not actually read the PRDs that are generated. In the grilling sessions he makes sure he and the AI are on the same wavelength so there’s no need to review the resulting document. Why would he? Doing so would basically only test the LLM’s ability to summarize.
Should he optimize the plan? Matt doesn’t think optimizing the plan to death adds a lot of value. Things will change afterwards anyway.
To see examples of a PRD and issues generated from it, check his course-video-manager repository, in particular the closed issues.
Now that we have our destination, how do we split it? Matt likes creating a
Kanban board out of it.
He created a skill to do this: /prd-to-issues
(source).
As you’ll see in that skill, Matt instructs the AI to use vertical slices. LLMs love to code horizontally, so per layer (database, business logic, frontend). This means you don’t get feedback on your work until all layers are done. If you slice vertical layers, you can test the entire flow sooner. (Also known as “tracer bullets” if you’ve read The Pragmatic Programmer.)
With the Kanban board setup, it’s easier to parallelize working on tasks. And once we have the issues that can be worked on, the human can step out of the loop.
For implementation use the /tdd skill
(source). It does red/green
refactors: write failing test first and then make it succeed. This not only adds
(good) tests to the codebase, but starting with the tests it’s harder to ‘cheat’
with writing the tests (you cannot write the tests to match the implementation
because the latter does not exist yet).
How do you conform with existing architecture, coding standards, API design, constraints, etc?
- Push instructions to the LLM (e.g. in
CLAUDE.md) - Pull: give the agent an opportunity to collect info, e.g. via skills.
For the implementer you should use the pull strategy so it can pull what it needs. For the reviewer use push (these are our standards, make sure they are adhered to).
You absolutely need to have feedback loops for the AI. The quality of your feedback loops directly affect the quality of the output.
As you may have noticed, there are two types of work when building something:
- Human in the loop (HITL) tasks (like planning) which need the human
- Away from keyboard (AFK) tasks (like implementation) where the AI can work autonomously
To recap the process thus far: you have an idea, you have the grilling session with the AI and this results in a PRD, which gets turned into issues on a Kanban board. These are HITL steps. Now the AI can take over and handle implementation where one or more agents work (the night shift so to speak). Once the AI is done, the human steps back in the loop for the QA/review step.

Matt Pocock discussing the phases in the whole process from idea to finished implementation
And yes, we do need code review. There is no way to avoid this. If we delegate coding to the agent in small PRs, we have to review more code. Matt doesn’t feel good saying that, but it’s his honest answer. The QA step is also where you can impose your opinions on the agent. Note that in the QA phase we also create more issues on the Kanban board.
You can and should have an automated review step though. Only QA manually afterwards. But be careful that the automated review isn’t done in the “dumb zone”, you want to review in the smart zone.
Frontend in particular is tricky. It needs human eyes. AI is not very good at that yet. But you can ask it to create a couple of prototypes to trigger a feedback loop with the agent.
So how does this work in a team? You involve the team in all HITL steps. And while the idea, research, prototype steps look linear, in the messy world you’ll bounce back and forth between those phases.
What if you have a bad, complicated codebase that even humans do a bad job in? How do you improve that? If your files are “shallow modules” (small files with little functionality), it’s hard for AI to navigate. It has to manually track through the repo. Also hard to draw test boundaries. Hard to test interaction between modules. Should the tests mock other modules?
Building a codebase that is easy to test is essential, because the feedback loop
is better. “Deep modules” are better; these are modules with more functionality.
Dependencies are more clear. So how do you go from a bad codebase to a good one?
How to group modules? The /improve-codebase-architecture skill
(source)
will find places to deepen the modules.
(The concept of shallow/deep modules come from the book A Philosophy of Software Design discusses dependencies.)
If you take only one thing away from today: use the /improve-codebase-architecture skill
You need to have (enough) control over the thing to be able to fix it. The PRD contains which modules are updated, it also helps you keep in control of the beast. Because we delegate more, we lose sense of our codebase. By building deep modules (big shapes), it’s easier to have their mental models in your mind. You don’t need to code review all details in a module, you only need to make sure the shape does what it needs to do.
Code is important, so understanding the tools deeply make you a better developer and you’ll get more out of AI.
When using plan mode, you can tell in CLAUDE.md to be terse (“when talking to
me, sacrifice grammar for the sake of concision”). This helps when reading the
plans. But Matt dropped this in favour of the grilling session where he and the
LLM came to the same shared understanding and he no longer needed to read the
plans.
Does he keep the markdown plans for future reference? No clear answer. Matt is wary of outdated documentation (names and requirements have changed). He tends to get rid of the plans and marking the issues as closed.
What does he think of Beads from Steve Yegge? It’s another way to manage Kanban boards.
Sidenote: Sandcastle (also created by Matt) is an orchestrator. It takes Ralph loop from sequential to parallel.
Matt is not selling a way of working. He does recommend buying old programming books (pre AI) since they contain a lot of wisdom that is still applicable.