AI Engineer Europe 2026: Keynote/Session Day 2
Table of Contents
The third, and final day of the AI Engineer Europe 2026 conference. The format of the day is similar to the previous day: kick the day off with keynotes, then breakout sessions and close with keynotes at the end again. Today I spent most of my time in the AI Architects track.
Building pi in a World of Slop — Mario Zechner
Pi is the engine inside OpenClaw.
Mario has several issues with Claude Code. To name a few: the system prompt changes on every release, zero observability, zero model choice, almost zero extensibility. He gravitated towards OpenCode as a replacement. But Mario found some design choices he did not like.
Started developing pi. It contains four packages:
- pi-ai: a unified LLM API
- pi-tui: a terminal UI framework
- pi-agent-core: an agent loop for tool execution, validation, event streaming and message queuing
- pi-coding-agent: the CLI
Pi has four tools:
- Read
- Write
- Edit
- Bash
That’s it.
It is in YOLO mode by default (in other words: it can execute commands without asking for permission). You need to implement your own guardrails that fit for your security needs. You can ask pi to implement those for you if you want.
Pi is extensible:
- skills
- prompt templates
- themes
- extensions: tools, command, shortcuts, compaction, etc.
All of these hot-reload.
How do you build an extension? You don’t. You specify what you need, and have Pi build it.
But none of this is about pi. It’s about taking control of your own tools.
Clankers are ruining OSS. Mario auto-closes new PRs that look AI generated with the message that the user should try again. Since Clankers don’t read this, he gets rid of the bots this way. Users that indeed try again are not blocked the second time.
Agents are merchants of learned complexity
Models are trained on bad architecture decisions and cargo cult best practices. So it’s trained on garbage. The model fills in blanks in your specs with garbage from the internet.
Humans work differently since we feel pain and fix things to resolve/prevent the pain. Agents don’t learn the way we learn.
How we should work with agents:
- Scoped, so that the agent doesn’t need to load tons of code
- With a closed loop so the agent can evaluate its own work
- Nothing mission critical (instead: dashboards, debugging tools, etc)
- Work on the boring stuff or things you haven’t had time for yourself
- Reproduce cases from user issues
Most importantly:
Slow the fuck down
Think about what you are building and why. Also learn to say “no”. It’s easy to add features, but are they the right features to add? Limit generated code to what you can review. And do review every line if it’s critical code.
The Friction Is Your Judgment — Armin Ronacher and Cristina Poncela Cubeiro
Agents initially felt like an unlocked secret: you get more done. Now you have to use them or you fall behind. It is not sustainable to do reviews and have time to think. It’s addictive. We are tricked into thinking we are doing more work. But we have less time to reflect on whether we are even doing the right thing. It is hard to know when to stop.
Before agents there was a balance between creating and reviewing code. But the creation part is now amplified. The parts the engineer still has to do are not amplified. As a result reviews are skipped or rubber-stamped.
The moments where you want to skip thinking are exactly the moments where it matters most.
Agents are optimized to write code that runs. They are not as good at making an overall good design. Agents introduce more code paths and local failures. And a degrading codebase reinforces itself: the agents will create worse code.
Libraries have clearly defined problems they are solving. And they likely have a simple core. Products, on the other hand, have more interacting components: flags, permissions, billing, etc. The components are more intertwined. One of the problems with that is that the context window cannot hold the full picture.
Your codebase has become infrastructure. So you have to design it in a way the agent can read it. To have an agent-legible codebase you need to have:
- Modularization with clear boundaries so agents can work in a single area at a time
- Known patterns and conventions the agent can use for pattern-matching
- A simple core (push the complexity to layers above)
- No hidden magic. If the agent cannot see it, it cannot take it into account
Examples of mechanical enforcements:
- No bare catch-all. This forces the agent to think about error handling
- No raw SQL outside the abstraction layer to preserve the query interface
- Use components for the UI
- No dynamic imports
- Enforce unique function names so it’s easier to
grepfor a name - Use
erasableSyntaxOnlyTypeScript mode
In pull request reviews you should separate the input going back to the agent from what needs to go to a human to make a judgement call.
We still have to go slow. It becomes harder to understand what is going on in the codebase. This makes cleanup also harder. It’s harder to judge the state of your codebase.
While we like to remove friction, some friction is useful. It makes it possible to steer the project. The friction isn’t your enemy, it’s your judgement.
Context Is the New Code — Patrick Debois
We are prompting to turn context into code. But we are also transforming code back into context in the form of skills.
Patrick is talking about the context development lifecycle today.
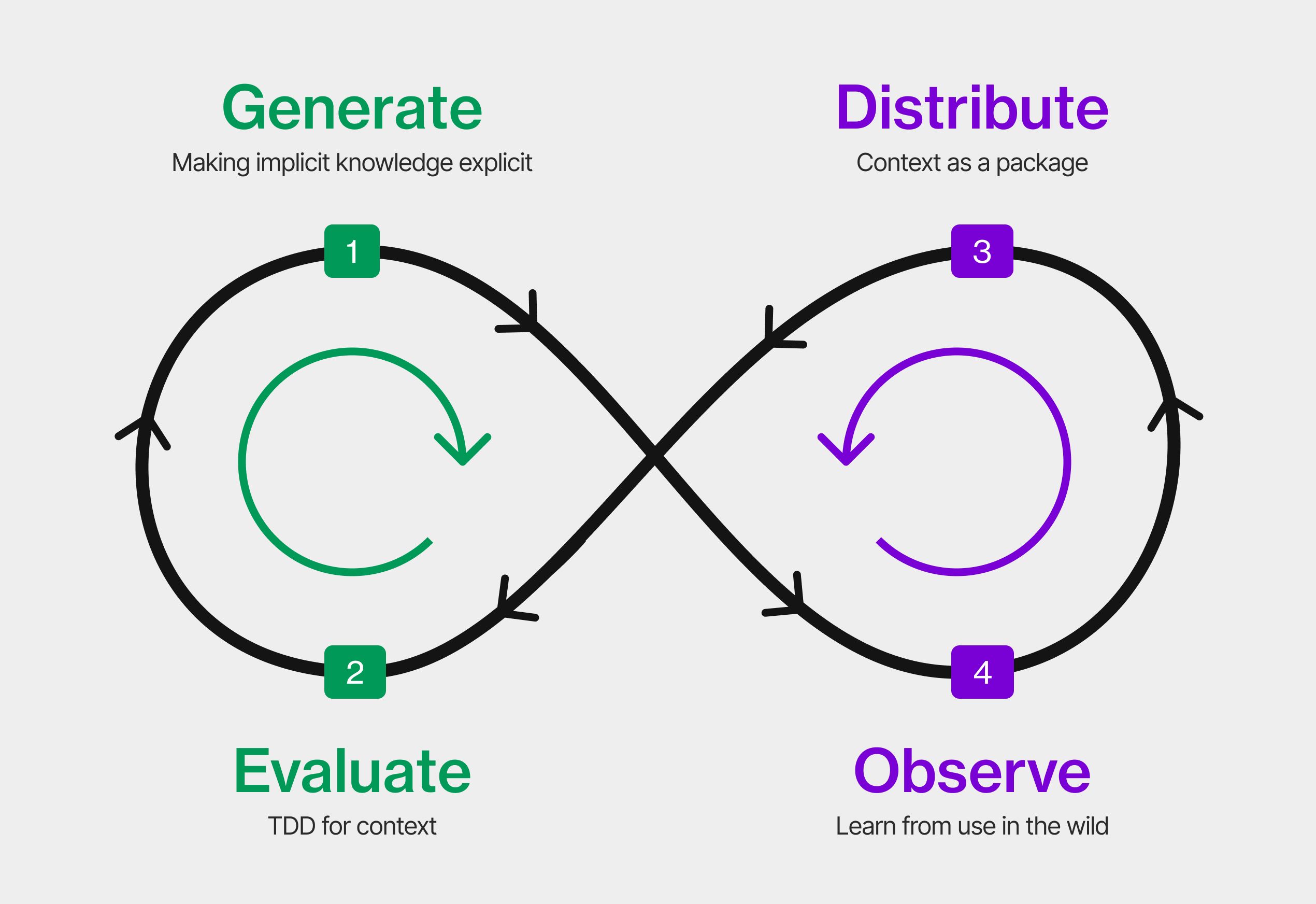
Patrick Debois explained the Context Development Lifecycle. Image taken from his article since I didn’t get a picture of it
Generate: create & curate context
Prompting is using humans as a context engine. If you want to get advanced: create
rules/instructions (AGENT.md or CLAUDE.md) to have reusable pieces of
context. You can also bring in context in the form of library documentation or
pull context from other places (context connectors, like MCP). But spec
driven development is also a form of context.
Evaluate: test & measure context quality
We’re not yet writing evals for our code context. We could validate our skills
(more or less linting). Use LLM as a judge if the generated code matches the
criteria. Compare the outcome with code generated without the context in your
AGENT.md to see if the context has an effect.
Once a judge gets agents and can do stuff, you basically get an end-to-end test. The tests give feedback what is working and what is missing. We can generate actions from there to improve context.
Can we run this in CI/CD? That’s hard, because it’s not deterministic. Better to run e.g. 5 or more times to see if it works most of the time.
Distribute
What if you want to reuse context in multiple projects/teams? You want to package the context in one way or another. Then the question becomes: how do you discover the skills? Via a skills marketplace. But most skills on there are crap. (It’s still useful to learn from others though.) A skill contains context, code, etc.
We’re also going to have dependencies and thus dependency hell.
We’ll need security and scan the context. (Snyk has options for this.) Who built this skill, with what model? We’ll need a skill SBOM.
Observe: monitor and improve in production
If you maintain a skill as something someone else can use, how do you get feedback how it’s working for others? Look at agent logs. Agent traces. Any feedback on a PR that it’s not correct is also feedback.
What about running code that’s running in production and was created from a context? You could e.g. use Hud
Agent sandboxing. Is code running in production doing strange things? Having a context filter is like a WAF and can prevent prompt injections. Use harness engineering.
Context is the fuel. Coding agents are the engine.
Related articles:
- CI/CD for Context in Agentic Coding: Same Pipeline, Different Rules
- The Context Development Lifecycle: Optimizing Context for AI Coding Agents
- Harness engineering: leveraging Codex in an agent-first world
(Full disclosure: Patrick works for Tessl.)
Most Enterprise Agentic Projects Are Doomed — Here’s Why — Jess Grogan-Avignon and Jack Wang
The presenters work in the world of large enterprises. A bad deployment can take down critical infrastructure. Control, process, repeatability and governance structures for human speed, not machine speed.
Only 12% of the companies are “AI Achievers”. The other 88% of them remain stuck and are falling behind.
Things that have made companies successful are now holding them back in the time of AI.

Jess Grogan-Avignon and Jack Wang about enterprise tensions that could hold agentic projects back
- Speed
- Enterprise speed is running at human speed (with practices such as security
reviews, deployment process, etc). Corporations have not invested like tech
companies have. An example: an application took 2 weeks to build, but 12
months to get it into production.
Approval infra hasn’t kept up with the speed at which the supply of code is growing. To go faster, every human step in the process should become executable, adaptable code.
- Value
- Needing a business case is not wrong per se. However, they assume scope,
solution, expected value and cost to deliver are known beforehand. But when
the cost to prototype drops massively, you can more easily test things that
were economically impossible before.
Enterprises need to think as a VC: take a bit of risk, not everything will turn into profit. Try out things.
- Delivery
- Treating a scientific process like software feature delivery. Utopian design
upfront with guaranteed performance and status updates. Instead of building
the thing.
IT is not the problem. The team needs to upskill product managers, architects, etc around building confidence.
- Trust
- Completed features are not the most valuable thing you ship. There is a large
trust gap. The trust you build when using an AI is the most valuable. Trust in
content quality, accuracy, security, reliability.
Agent autonomy is gated by evidence in outcomes, you need to earn autonomy. Use what the user is saying to iterate. Shadow mode -> advisory mode -> controlled autonomy -> expanded autonomy. Engineer for trust, not completion.
- Moat
- What is unique for you? When your customer touches our product. Deployment is the starting line, not the finish line. How fast can you iterate? Continuous, compounding feedback loop.
Prescription to succeed:
- Start now: deliver differently and measure in confidence
- Make finance a transformation partner, not a gatekeeper
- Make governance speed an engineering problem
- Redefine your moat as what you compound from today
The Domain-Native AI Organization: How to Leverage Domain Expertise — Chris Lovejoy
We often do not have deep understanding about the processes we are automating. Use domain experts as oracle, evaluator or architect.
- Oracle: directly adds expertise
- Evaluator: define and measure quality
- Architect: build self-improving systems
Most common mistakes:
- Not hiring domain experts (or too late)
- Wrong kind of domain expert
- Not fitting them in the organization properly
Do you need domain experts? Yes! Appraising AI quality requires judgement. And judgement requires domain expertise.
CI/CD Is Dead, Agents Need Continuous Compute and Computers — Hugo Santos and Madison Faulkner
Agentic software is breaking traditional CI/CD. Why is CI/CD dead? At agent scale you have more PRs and more repos. But it still takes the same time to review and verify. Merging all different versions together becomes impossible.
Machine latency in the CI/CD pipeline was hidden behind the ‘slow’ humans. With agents the pain points become clear.
Today we have the human in the loop: we validate the PR. So each time a PR is rejected the agentic software can update the PR fairly quickly only to be blocked again by the human. But since this means there are only so many changes going on, we have a relatively big window to get your stuff merged.
The PR as a unit of work was designed for humans. CI matters because it validates your work. It also facilitates coordination.
Hugo explains a loop we have today: intent + plan (what are you doing) goes into an agent harness loop. The agent will check out your code. Then goes to internal validation to make sure the change is correct. It then reports back to the human for external validation (does it look good?). When done, go to merge queue. This is fast, but not fast enough because there is a human in the loop.
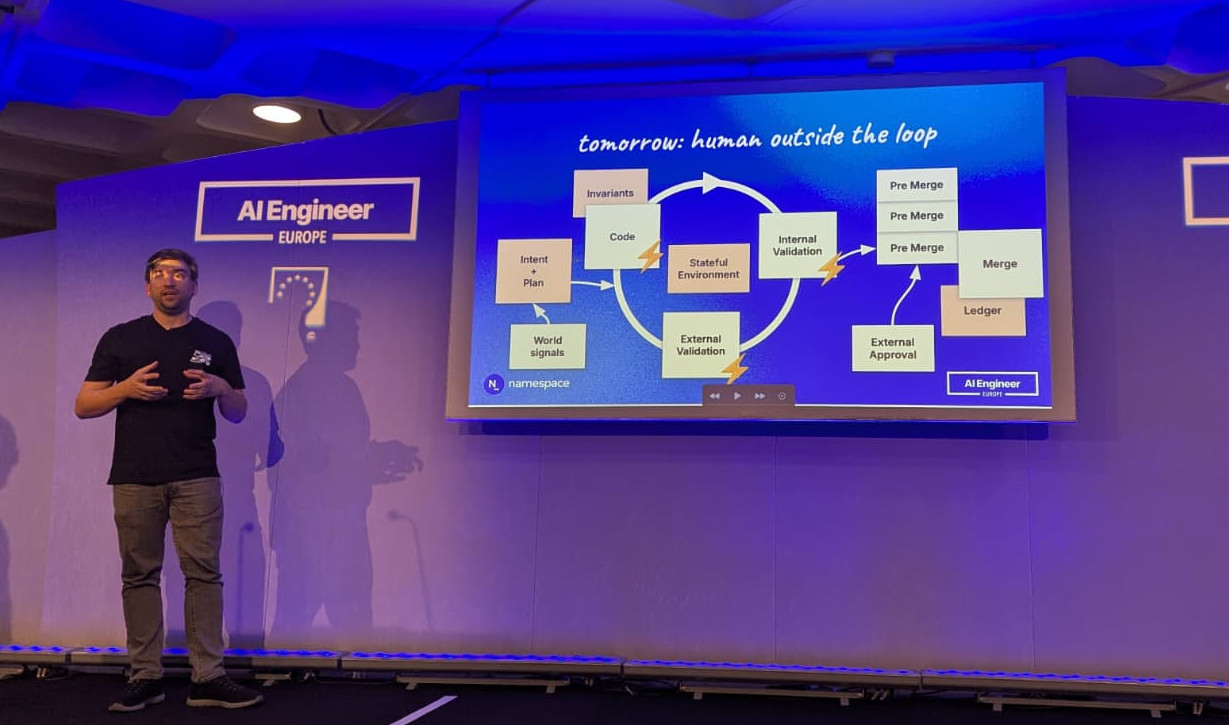
Hugo Santos showing the human out of the loop setup of tomorrow
Tomorrow the human will be out of the loop. We’ll have all kinds of LLMs (e.g. one with a security focus, another one with a different focus, etc) to do the external validation. The human only needs to approve a change once it’s in the pre merge queue. So the human is still gatekeeping, but later in the process.
Software Engineering Is Becoming Plan and Review — Louis Knight-Webb
What are we even going to do in the new AI era?
Work humans do:
- Plan
- Write code
- Review my code
- Review other people’s code
If we look at 2021, most time was spent writing code and reviewing other people’s code. If we look at 2025, there is little actual coding; most time is spent reviewing other people’s code.
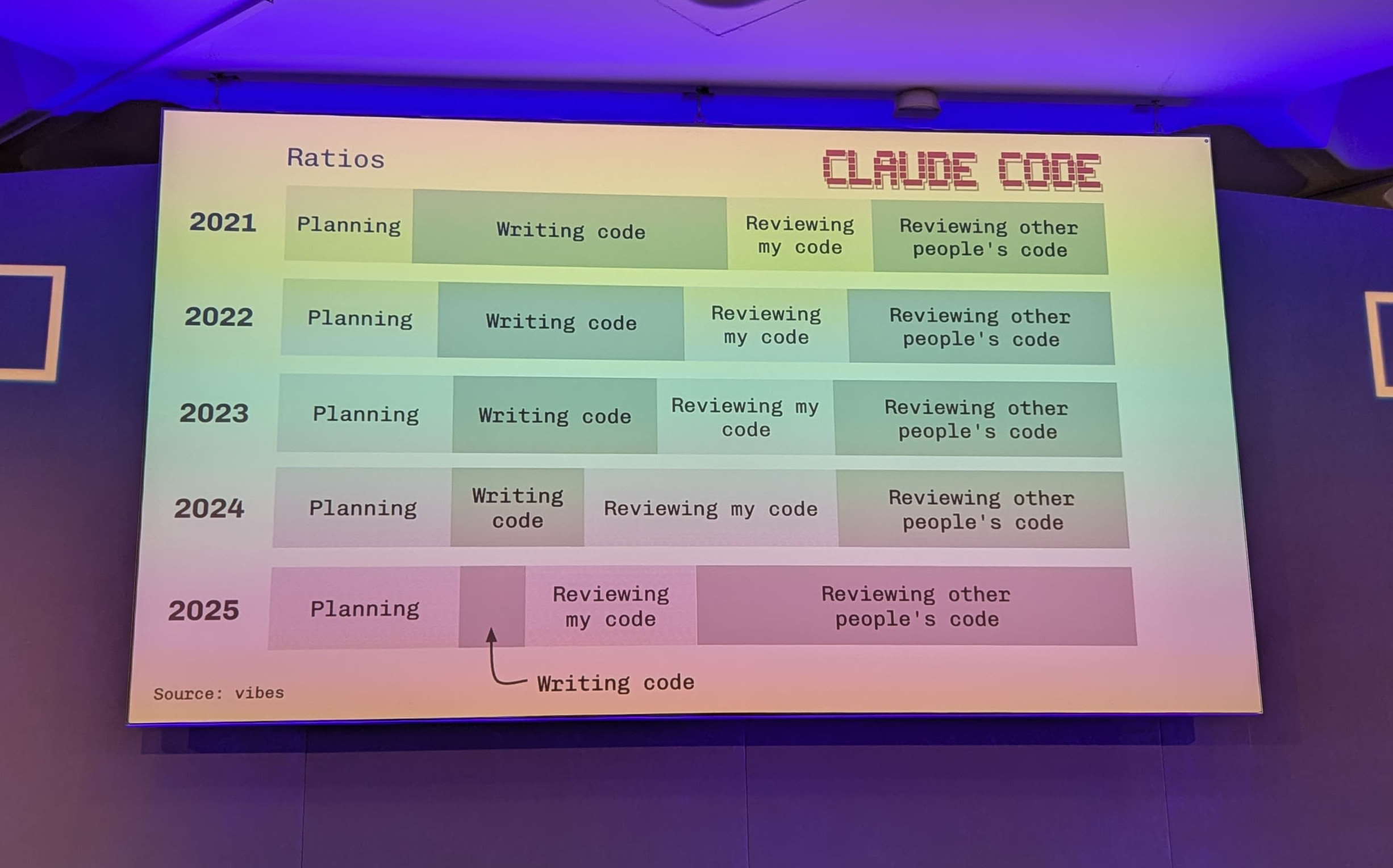
So work got displaced. The time we no longer spend on coding (because the AI is doing that now) mostly changed into planning and reviewing code.
There are basically two modes to work in:
- Spend a lot of time planning (create a comprehensive plan doc, interrogation, etc). You spend more time planning, but the coding agent can run longer and there’s less time needed for review.
- Spend a lot of time reviewing. Loosely define prompts, at the cost of more manual QA work. If you spend less time planning, the coding agent yields results faster, but there’s more back and forth with agent delivering half baked work.
The mode you’ll want to use depends on the type of work. Plan heavy mode works well for refactoring/migration. For new features heavy planning works for backend tasks, but for the frontend the review heavy mode is a better match.
Spending 5 mins of planning saves you 30 minutes of time reviewing code.
The time an agent can run before human intervention is needed has increased over time. This is good: you want to minimize the time you are spending with the AI. Most of the time the back and forth is done by the agent itself.
When the agent takes longer than 5 minutes, waiting on the AI (and slacking off) is not realistic. So when agents run longer and longer, you need to change your way of working. One option is parallelism (have multiple agents working at the same time) Vibe Kanban is a tool to help you with that approach.
What should the future look like to help the human?
- Focusmaxxing: embrace the fact that you cannot context switch every 30 seconds, instead build to get the most out of the humans
- Write tasks
- QA (websites, APIs)
- Code review
- Shepherd the change until it’s deployed
Then the talk took another turn.
Recently Louis decided to shut down the company behind Vibe Kanban. On stage he instructed his agent to write the Goodbye bloop blog post (with a prompt he had prepared beforehand). Don’t worry though, the project will continue as open source and be maintained by the community.
How Building with AI Can Double the Throughput of Your Engineering Team — Brian Scanlan
Brian works for Intercom. They are the company behind Fin.
Change is hard. You need clear and executive guidance. How to enable change:
- Update job descriptions and expectations
- Constantly talk about the urgency of AI adoption
- Reward great work (financially, socially and publicly)
- Give people room to learn, enable them and give them access to tools
- Be very specific about what you want to see and how it is to be done
Standardizing on a single, skill driven AI platform helps. Prove that it works, optimize its usage. Connect it to everything. Anything the human can do on their laptop, the agent should also be able to do. (You’ll need to be in control of your environment to make sure it doesn’t do anything bad though!) Start using the platform for all technical work. It will make mistakes initially, but it will become a flywheel where it will become more powerful over time.
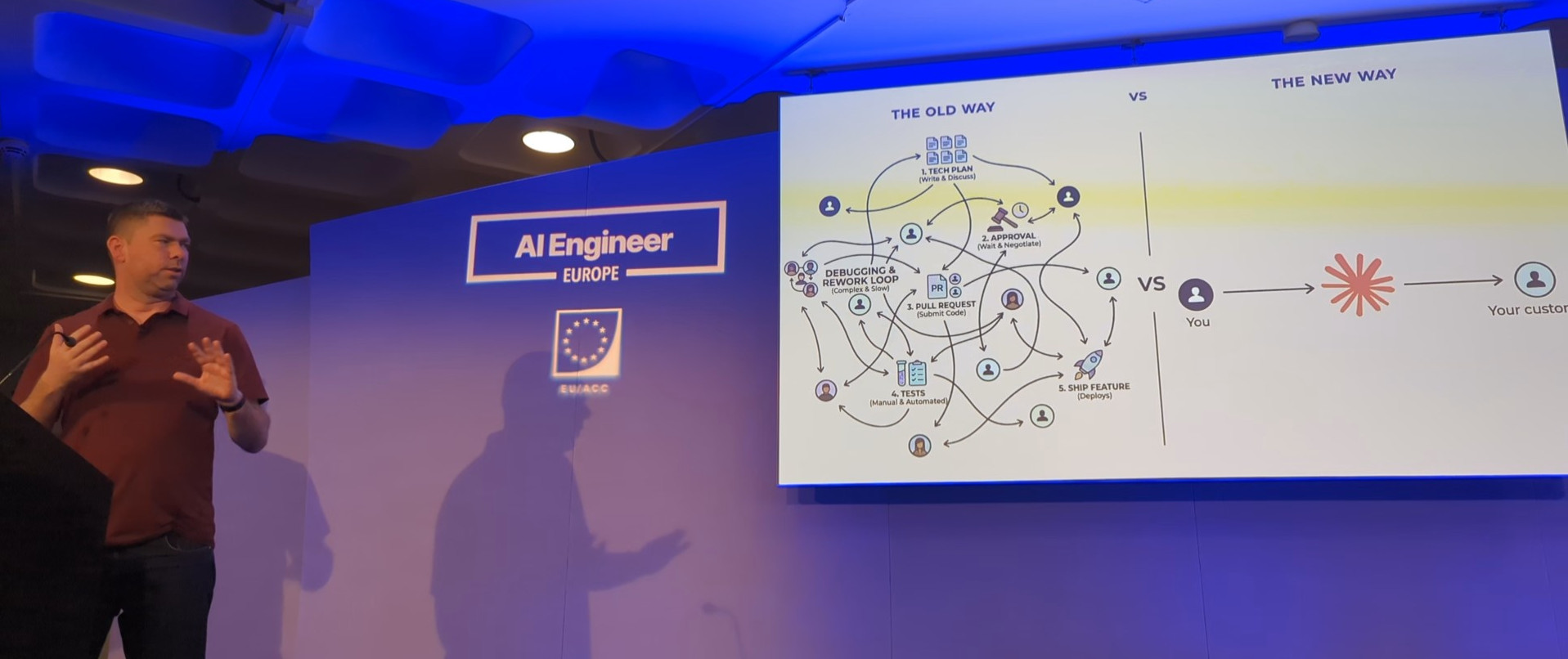
Brian Scanlan illustrating technical work being replaced by AI
Engineering is changing. The engineers focus their time on writing specs, validation and improving the agents. The agents write, test and review code.
Internal tools at his company are deprecated in favour of first-class vendor replacements (like Anthropic/Claude Code).
Give agents problems, not tasks
Agents should figure out the necessary tasks on their own. They focus on durable, high quality, sharable skills.
Current bottleneck: code review.
Intercom has extensive feedback loops via lots of hooks to Honeycomb. They measure things like skill invocations, failures, etc.
A side-effect of using AI more was that their defect rate is going down. This wasn’t a goal, but a natural consequence.
Relevant link:
Agents Don’t Do Standups: Building the Post-Engineer Engineering Org — Mike Spitz
From “how do we help engineers output more?” to “how do we make agents faster?”
Scrum did not survive
Rituals designed for humans don’t work for agents. Ceremonies became huddle sessions.
Specs are turned into LDDs (lightweight design documents) which become tickets and PRs.
| Humans | Agents |
|---|---|
| Sprint planning | Don’t need 1hr estimation sessions |
| Daily Standup | Update tickets automatically |
| Sprint refinement | Generate tickets via LDDs & flag issues, make sure tickets don’t depend on each other |
| Retro | Metrics replace anecdotes |
How do you start?
- Pick the engineers with development and broad system knowledge
- Scale slowly!
- Experiment in non-critical systems
Also keep in mind that:
Not everyone can drive a sports car
It’s going to be hard for a few engineers. The curious engineer will smash this.
Some guardrails:
- Verifiable deterministic tasks (unit tests, e2e tests, linters, PR prerequisites)
- Agentic code review (human steering, agentic review; opinionated comments are easy to offload)
- Tiered human in the loop (heavy human review at system design, light review at code (except security), heavy review at end for product feel)
Prerequisites for autonomous loop:
- Composable skills (all parts of development are abstracted into composable skills)
- Agent-involved stages (agent involved at every stage: spec, LDD, ticket/branch/PR creation, self-testing, self-QA)
- Self-healing agents
- Human multipliers (allow humans to parallelize)
What do the humans do?
- Security (ensure no shortcuts were taken by the AI)
- Product feel
- Scale & engineering complexity for task (Are we spending tokens on work we don’t need to do? Is the agent over-engineering?)
The playbook to get started:
- Start with boring, repetitive tasks
- Remove as much redundancy from the process as possible
- Make sure the good patterns are turned into skills
- Build guardrails before autonomy
- Build this with your best engineers
- Do not onboard everyone all at once
- Do not try to create a “one size fits all” approach
- Do not be conservative, otherwise you’ll get behind (compounding effect)
- Do not try to do too much at once, you want a phased approach