AI Engineer Europe 2026: Keynote/Session Day 1
Table of Contents
Day two of the AI Engineering conference. Yesterday was filled with longer talks where the speakers could go more in-depth. This day consists of shorter (usually 20 minute) slots of talks and keynotes.

The New Application Layer — Malte Ubl
AI is changing how we build and what we build. Is there a place for the software engineer in the future?
Agents are a new kind of software. They are both the builders and users of software. They allow us to automate things that were economically unviable in the past. But with AI, this changes. Lots of software was too expensive to write (compared to the benefits it would bring). Also, companies are making different decisions with regard to buying from SaaS companies versus making it themselves. The cheaper the software is to make, the more software there will be. This leads to more work for software engineers.
As AI Engineers, our job is to build the next application layer: agents.
Archetypes of practical non-coding agents:
- Always running (24/7)
- Compresses the research (in the chain of business event -> research -> human decision, we can have the AI do the research)
- Surfaces the hidden information (lots of info, but you cannot practically use it)
- The boring things (more time for the human for the interesting tasks)
We also need to realise that software is for agents now. For example, 60% of the visitors of the vercel.com page are agents.
Not writing the code yourself also makes us less opinionated about the infra. It “just has to run”.
We should also have agentic security infrastructure. We need to have an open mindset for how to change things.
The new application layer can thrive independently of models. Now model A is the “best” today, but tomorrow it’s model B. We as engineers should provide a stable interface.
Europe is the leader in AI Engineering. Not models though. But the model companies are commoditising. The application layer is where the real innovation happens.
Harness Engineering: How to Build Software When Humans Steer and Agents Execute — Ryan Lopopolo
Use the models to do the full job. Lean into the idea that the models are software engineers.
Code is free
Hiring the “hands on the keyboard” is constrained by token budgets nowadays. We need to constructively use this capacity. The human skill sets that are now needed are delegation and systems design.
The models are good enough. Code is free (to produce, maintain and refactor). Your role is to unblock your team and your team is infinitely large. Your job is to make use of that team.
Human time and attention is scarce. How do we effectively use it? When we are no longer blocked by this, we can work on the low(er) priority issues. We have infinite coding resources, right? Humans don’t need to concern themselves with implementation, but specs and guardrails. Our job is to build systems and structures to make our teams effective.
What does it mean to do a good job? Used to be years of experience in the field. Lots of little decisions in everyday work. But agents have seen more code than we have seen. We need to write down the non-functional requirements so that the agents can use this. Figure out what the agents are struggling with. Put guardrails in place to guide the agents. Move on to higher level tasks.
Having a single QA expert in the team who can write a good QA plan can benefit the whole team. Same goes for other experts: one engineer has more impact on the whole team than before.
How can we help the agents to make the correct decisions?
- Continuously run review agents
- Check if the code has a secure interface
- “Lint” for non-functional requirements
- Figure out why we are spending time on correcting agents and fix the problem so you can move on
- Adapt your codebase to match the world today, e.g. limit file size so they fit in the context window
- Have good error messages with resolution steps. This helps the agent resolve issues itself
Everything is a prompt: rules, skills, error messages, PR comments, et cetera.
Just build things. Do not hesitate to have the agents do the full job.
Why building eval platforms is hard — Phil Hetzel
Evals and observability are related. Evals is what you do before hitting production, observability is what you do when in production.
Why are evals important?
- LLMs have extreme variability (we love them for it though)
- Agents are becoming the norm, people have come to expect them when interacting with your company
- You need to be confident with the agent’s performance
Evals are not a hard problem: gather a bunch of example inputs, loop through them with the agent and publish the result. Right? Actually it’s way more complex. Think about tracing, alerting, online scoring, topic modeling, etc.

Phil Hetzel speaking about the eval iceberg hidden under the surface
Different stages of doing evals:
- A spreadsheet plus a
forloop. It’s a great place to start, no barrier to entry. However, it’s more about documenting and not really experimenting, and it is hard to compare experiments. It’s also a cumbersome process. - Vibe coded UI. Nice next step, probably has proper persistence (database). It’s a bit more bespoke to bring others into the fold. But it’s still more of a reporting tool.
- Encouraging experimentation. Give a user access to an agent configuration plus a sandbox. Allow the users to tweak prompts and parameters. (He demonstrated with Braintrust). Still no access to production traces.
- “The Flywheel”. This is where observability and evals are connecting. Understanding actual user behaviour. This unlocks the feedback loop. Downside: you now have to manage the eval platform, at the pace the industry is moving. More importantly: agent traces are nasty (and not like normal application traces), very large and numerous.
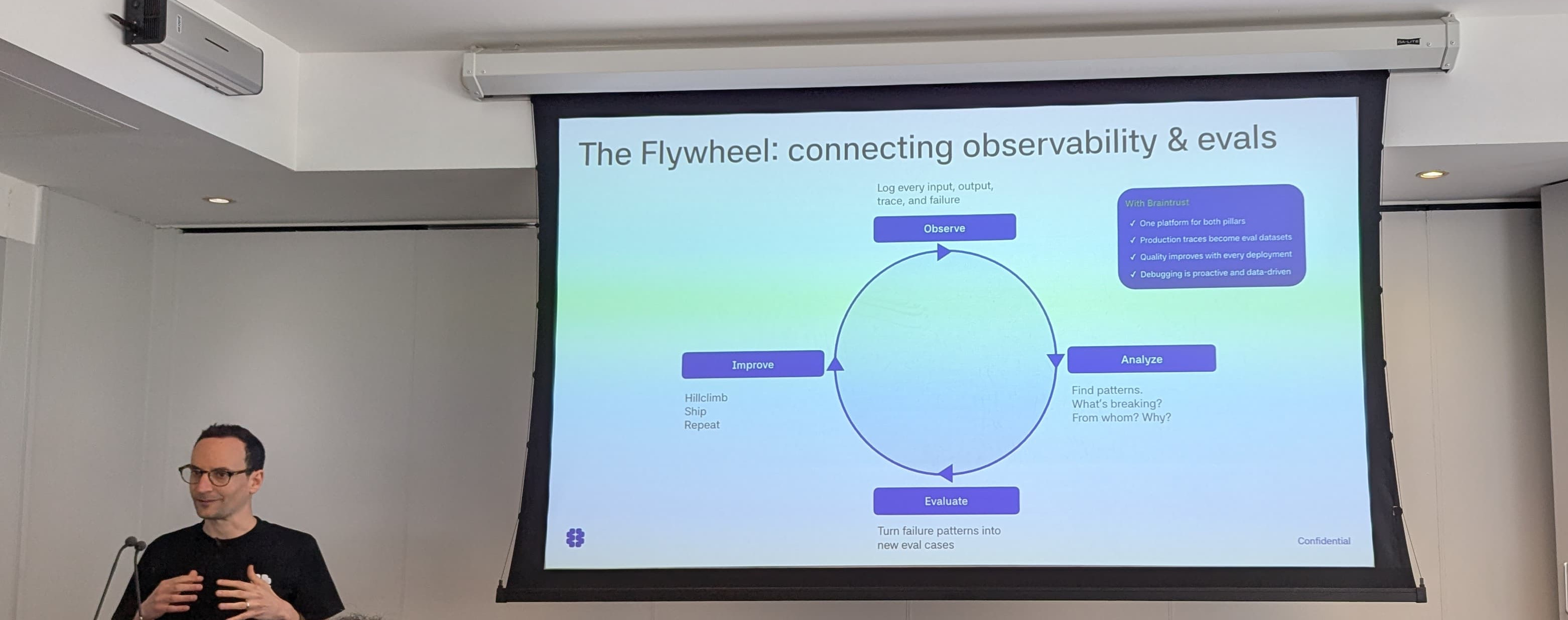
Phil Hetzel speaking about the flywheel: observe -> analyze -> evaluate -> improve -> etc
This is a new problem because of the specifics of traces: larger spans, highly unstructured, difference in read patterns. And while these aspects individually are not unique problems, the combination of them is new.
Building the right system: specific for agent traces with multipersona workflows. This allows you to measure agent quality at scale, delivering near real time feedback.
Looking forward:
- Surface unknown-unknowns via topic modelling techniques
- Build the platform for users and agents
- Perform observability via an AI proxy or gateway
What Breaks When You Build AI Under Sovereignty Constraints — Bilge Yücel
Sovereign AI is “the ability of an organisation to design, deploy and operate AI systems on its own terms.” In a practical sense: this means having explicit control over data flow, model choices, infrastructure, observability and operations.
The pillars of sovereignty:
- Data sovereignty
- Data should be stored in “trusted jurisdictions”. If you send your data to a model running in the US, you may already not be compliant anymore.
- Infrastructure sovereignty
- Maximal control: airgapped (EU AI act safe). Maximal convenience: SaaS (CLOUD Act risk)
- Model sovereignty
- You do not want to tightly couple with a specific model provider. You want to be able to swap without architectural changes.
- Operational sovereignty
- Monitor how AI systems behave, have the human in the loop, manage versioning and updates to models and applications.
Sovereignty is a spectrum. Some sectors need more sovereignty (finance, healthcare); some need less (e.g. startups).
What are the engineering challenges? What do you do and what do you break?
- Replace the frontier API with a self hosted model. Consequence: translate API logic
- Private data to required jurisdiction. Consequence: managing multiple databases and instances.
- Replace managed infra with on-prem. Consequence: you discover vendor lock-in and are limited by your hardware.
- Incorporate observability and tracing. Consequence: you have to do version control of the whole system.
Haystack solves some of these problems. It has:
- A consistent interface
- Explicit data flow (know what data was where)
- Serializable to YAML so easy to version
- No black box or hidden assumptions because it is open source
(Full disclosure: Haystack is a product from Deepset, the company Bilge works for.)
Architecture:
- Guardrails (check input)
- Agent (with LLM)
- Guardrails (prevent leaking info)

Bilge Yücel showing a sovereign architecture
Sovereignty checklist:
- Can you swap your models without changing the application logic?
- Do you have reproducible run logs stored in a compliant way?
- Can your team respond to an incident without needing the help of the hyperscalers?
Related blog post: AI Guardrails: Content Moderation and Safety with Open Language Models
Software Engineering + AI = ? — Gergely Orosz and swyx
Gergely is the man behind The Pragmatic Engineer.
What does Gergely think about tokenmaxxing? It’s happening at multiple large companies. Token output is measured and e.g. shown on a leaderboard. This results in uncertainty: people start to think performance is also measured by token usage. Token count can be weaponized. The result: people start burning tokens by, for example, asking the AI instead of reading the docs just to get the token count up, even if the AI doesn’t do a good job of answering the question. Some companies even have a minimum token count. It’s a weird time to live in.
Is AI still making us faster? Experienced engineers were holding off, especially the older models on existing codebases. Targeting and measuring token usage came from the C-suite. They had the idea that if their company was not using AI tools they are probably not doing well. There’s a push to use AI.
Why are engineers putting up with that? For the same reason as we have weird leetcode interviews: they select for smart people willing to put up with a bullshit process to get the job. Big tech is a bit weird.
Individually, AI makes us go faster. For teams? Not always. It is hard to retrofit in some situations. An engineer is perhaps not much more productive. But enabling non-coding colleagues with AI unlocks the ability for them to not have to wait for dev but get things done themselves.
These times are hard to understand for us engineers:
- Using AI takes a long time to get good at it
- Knowing the theory behind it and how it works will not make you more productive
How is the role of a software engineer changing? Before AI the role was already changing. AI just sped it up. Startups were already moving fast with smaller teams. More roles collapse into the role of a software engineer (think of DevOps, QA). Now also product management. Software engineers need to know about the business, and take more responsibility.
“Everyone is an engineering manager now” (no longer a software engineer). This is absolute nonsense. Traditional managers take care of people problems, their growth path, etc. But with AI you don’t have to worry about a person. It’s more a tech lead role. You can do more and faster, but are still in control. It’s only orchestration, not management. With agents you have a faster feedback loop than with humans.
E.g. Uber is not building more features into their core product. Instead they are working on infra and people are building more. It’s a low risk way to be hands on with AI and learn. But also the codebase is too big for the context window, building separate things is easier. Plus: anything related to AI gets funded faster.
Taking AI infra seriously is not well understood. We’re learning from each other.
Keynote — Kitze
This talk was fast paced and very enjoyable. I can recommend watching it. (See the AIE Europe Day 1: Keynotes … starting at 8:08:46)

It Ain’t Broke: Why Software Fundamentals Matter More Than Ever — Matt Pocock
With the new paradigm (AI), we should probably chuck out the old rules to make room for new ones, right? There’s a “specs to code” movement where you write the spec and have the AI do the coding. You don’t look at the code. If there is a problem with the code, you go back to the spec and try again. This is driven by the idea that code is cheap.
But ignoring the code doesn’t work. A bad codebase is one that is hard to change. The Pragmatic Programmer has a chapter on software entropy. It basically means that if you do not pay enough attention to the design of the whole system, the codebase will become worse and worse. And this was exactly what he was seeing when he was running the compiler again and again when using specs to code.
Bad code is the most expensive it has ever been. Good codebases matter more than ever.
Software fundamentals matter more than ever
Common failure modes and how to avoid them by going back to old software practices:
- The AI didn’t do what I wanted
- No-one knows exactly what they want. There is a communication barrier between
you and the AI. The Design Of Design
speaks about “the design concept”: the idea of what you are building. You and
the AI don’t share a design concept. Hence the
/grill-meskill. Works towards a shared understanding. Use his other skills to generate a Product Requirements Document or issues. (See Matt’s skills repository for the skills mentioned in this talk.) - The AI is way too verbose
- You also see that in the interaction between a developer and a domain expert.
You need to establish shared language.
Domain Driven Design
also needs a ubiquitous language. In our case this is essentially a Markdown
file with concepts and what they mean. Use the
/ubiquitous-languageskill. This generates a file (UBIQUITOUS_LANGUAGE.md) with tables with terminology. - Code that doesn’t work
- Use feedback loops: static types, browser access to look around, automated tests.
- Doing way too much
- The Pragmatic Programmer calls this “outrunning your headlights”. The rate of
feedback is your speed limit. Related skill
/tdd: write test, make test pass. However, testing is hard (how big of a unit do you want to test, what to mock, what behaviour to test, etc). Good codebases are easy to test. (Because of better feedback loops and more clear boundaries.) Use deep modules: few modules with lots of functionality but simple interfaces.

Matt Pocock about deep vs shallow modules
- AI does not understand my code
- Again, use deep modules. Easier for the AI to understand the design. How to go
from shallow to deep modules? Use the
/improve-codebase-architectureskill. - My brain hurts
- The human cannot keep up. Again: deep modules make it simpler for you to understand the codebase. You can treat these modules as grey boxes. The AI can handle what’s in the blob. Design the interface but delegate the implementation.
Invest in the design of the system every day
Code is not cheap, it is important. If we think of AI as a programmer, you need someone above that, thinking on the strategic level. And that’s you! And that’s why fundamental software development skills are still important.