Google Webmaster Tools
Google’s Webmaster Tools provide the modern webmaster/developer with some nice tools to improve a website and the way the site is indexed. In this article I’ll focus on the crawler related tools. Specifically, how they helped me when I migrated from Plone to Django.
Crawler access
First up, crawler access (in the Site configuration menu). This
item offers three tools: you can generate a robots.txt file, test a
robots.txt file and request to remove a URL from the Google search
results.
For those unfamiliar with a robots.txt file: it is a way to give
instructions to a robot,
like the ones used by search engines to index your website. With the
tools in the crawler access section you can easily create such a file
to e.g. restrict access to your internal search pages. Besides
creating the robots.txt file, you can also test it by specifying a
URL and the tool will tell you whether it is allowed to access the
page or not. (Note: this is not a security mechanism. Robots can
ignore the instructions.)
In my case I only used the testing tool since I already had a
robots.txt file and just needed to adjust it.
Crawl errors
The next thing I’d like to discuss are the crawl errors (in the Diagnostics menu). Among other things, it shows you which pages Google expected to be on your site but could not find. This was useful since there were a number of pages that were not available anymore after migrating from Plone to Django. (Especially pages that I forgot were accessible.) For instance:
/author/markvlwhich is now just/about/front-page(the default page of the Plone site root) is now just/
Sure, I could have found those myself (and I probably should have), but it’s very easy to miss URLs that are referenced somewhere. This tool efficiently lists those missing pages, so I could add some rewrite rules in my web server configuration to solve the problems. (Note that the results can change, so you might want to check them regularly.)
By the way, it’s also a nice way to catch mistakes in the content: in once case I had a typo in the link from one blog entry to another. It popped up in the crawl errors and I was able to correct this.
Crawl stats
The crawl stats (also in the Diagnostics menu) display the Googlebot activity of the last 90 days. While there’s only that much you can do to control the way Google crawls your site, it was funny to see how some changes made an impact.
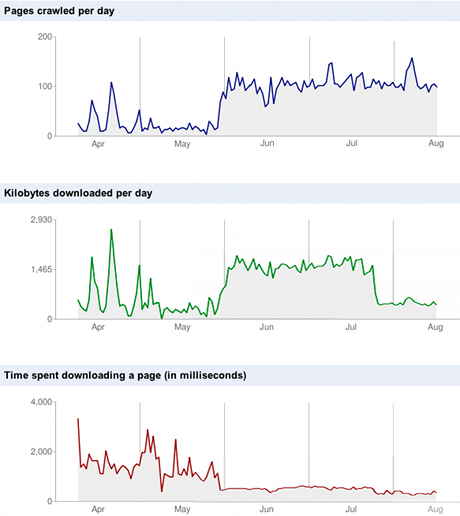
Crawl stats (composition of two snapshots I made of the graphs)
The first change, which is visible in all three graphs, is the migration to Django on May 31. Google clearly started crawling more pages since the end of May. As a logical result more bandwidth is consumed. However, less time is spent downloading a page.
The second change is most clear in the middle graph (kilobytes downloaded per day). I moved to a different server and enabled gzip compression on June 25. The move was planned but I might have forgotten about the compression if I hadn’t seen this graph.
Even more…
This article focussed only on a few of the available tools. There’s much more to discover, like an overview of the queries that returned pages from your site or the ability to upload a sitemap (and being able to view how many of the pages in the sitemap have been indexed).
I really think that using the webmaster tools is a valuable addition to a webmaster’s toolkit.